




使用Perl的秘密超模块让您的代码运行更快

大多数现代处理器都是多核的,然而Perl程序通常每次只在单个核心上以单线程方式运行。现在有了多核引擎模块——它使得在您平台的每个核心上并行运行现有的Perl代码变得容易,并在过程中获得巨大的速度提升。
要求
您需要安装MCE模块。当前的CPAN测试者结果显示它可以在多种平台和Perl版本上运行。您可以通过命令行使用CPAN安装MCE。
$ cpan MCE您不需要将Perl编译为启用线程以获取并行处理的优势,因为MCE可以通过fork、forks::shared或threads::shared通过子进程实现并行处理。默认情况下,MCE会检查是否存在线程模块,否则,将通过fork创建子进程。
理解MCE
MCE的文档将其实现描述为“银行排队模型”。本质上,MCE在每个主机平台上的每个核心上使用最多一个工作进程,并通过“块”在工作进程之间分配工作。一个块只是一个元素集合,例如数组切片或文件的多行。工作进程将以并行方式处理每个块。工作进程实际执行的“工作”通常是Perl子例程的执行。这将在下面的示例中变得更加清晰。
管理和分配块会产生一定的开销:因此,当您有大量要处理的元素且对每个元素进行的“工作”比基本的模式匹配更复杂时,MCE最为有效。在本文的测试中,我发现数据挖掘Web服务器日志时,运行时间减少50%是很常见的。
入门
开始使用MCE的最简单方法是使用MCE附带的三种基本自动化模型之一。基本模型是Perl的foreach、map和grep控制的直接替代品。模型会自动调整自身——默认情况下,它们使用主机平台上的最大核心数,并根据输入记录数和源类型选择最优的块大小。
让我们看看grep模型。下面的代码是标准的Perl代码;它打开一个nginx访问日志并打印来自机器人用户代理的日志记录数。
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
open(my $LOG, '<', '/var/logs/access.log');
my $count = grep { detect_robot($_) } <$LOG>;
say scalar $count;让我们修改上面的代码以使用MCE::Grep模型。下面是新的代码
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
use MCE::Grep;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
open(my $LOG, '<', '/var/logs/access.log');
my $count = mce_grep { detect_robot($_) } $LOG;
say scalar $count;这里的主要变化是
- 导入模块的“use MCE::Grep”行
- 将grep更改为“mce_grep”
- 从文件句柄($LOG)中删除菱形运算符
另一个区别是,此代码将比第一个示例运行得更快。快多少取决于平台和输入记录数。在我的测试中,我在一个四核处理器上发现,MCE::Grep始终比100-150%快,但使用更多核心时,预计这会增加。
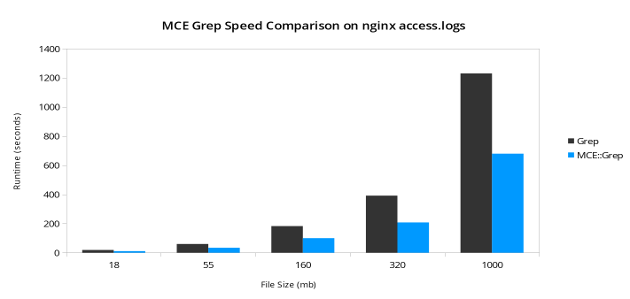
其他基本自动化模型MCE::Loop和MCE::Map与MCE::Grep非常相似。
与文件路径一起工作
MCE 还提供了一个专门的“mce_grep_f”函数,用于直接处理文件(该函数为所有 MCE 模型提供,例如 mce_loop_f 和 mce_map_f)。 “mce_grep_f” 函数需要一个文件路径参数。
use strict;
use warnings;
use feature 'say';
use Nginx::Log::Entry;
use MCE::Grep;
sub detect_robot {
return Nginx::Log::Entry->new($_[0])->was_robot;
}
my $count = mce_grep_f { detect_robot($_) } '/var/logs/access.log';
say scalar $count;然而,MCE 1.504 版本中这个功能是损坏的,但是修复起来很简单 - 只需插入一行。该模块的作者 Mario Roy 联系了我,并友好地提供了一份差异。我被告知,这个功能将在 MCE 的下一个版本中修复。(编辑:现在已在 1.509 中修复)
在测试中,我在 55mb 的日志文件上使用上面的代码测试了 mce_grep_f 函数,与 mce_grep 相比,我没有看到明显的性能差异,但是有报道称速度提高了 4 倍,所以肯定要进一步探索。
更改工作线程数
默认情况下,MCE 会为每个核心初始化一个工作线程。它使用以下方法检测核心数
- Linux:读取 /proc/stat
- OSX/BSD:执行 “sysctl -n hw.ncpu 2>/dev/null”
- Windows:使用环境变量:ENV{NUMBER_OF_PROCESSORS}
MCE 还为 Solaris、HP-UX 等其他系统定义了特定于平台的函数。假设 MCE 会正确猜测处理器数量,那么更改默认行为的原因可能只是要使用不到 100% 的可用核心。您可以使用“init()”方法做这件事。
use MCE::Grep;
MCE::Grep::init({max_workers => 3});上面的代码使用了 MCE::Grep,但所有 MCE 模型都提供了相同的 init() 命令。
更改块大小
当源类型是数组时,MCE 会根据输入记录数和可用工作线程数自动计算块大小。您可以覆盖此设置,但在我的测试中,我发现自动计算的块大小几乎总是最优的。以下是一个典型结果集,用于处理 55mb 的日志文件
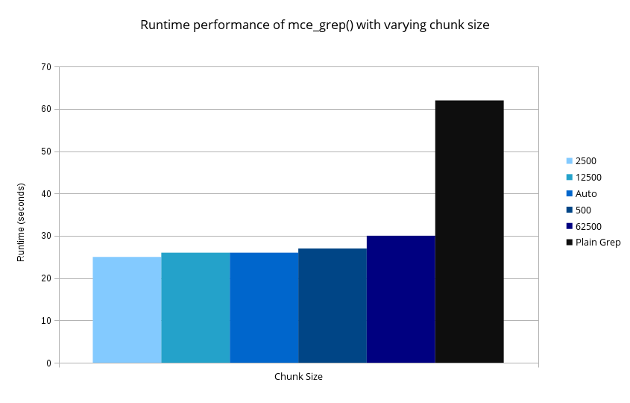
如果源类型是文件句柄,块大小默认为 2(模块的作者 Mario Roy 告诉我,这将在下一个版本 1.506 中改变)。因此,您可能需要覆盖块大小以尝试获得更好的性能。您可以使用“init()”方法做到这一点。
use MCE::Grep;
MCE::Grep::init({chunk_size => 500});由于在工人之间分配工作块的管理会带来一些开销,最优的块大小将是最小化块分配次数的同时保持工人忙碌均衡的一个。MCE 没有考虑的一个因素是“工作”的难度:即一个工人完成一个工作单位所需的时间。可能基于运行时性能开发某种动态块大小逻辑会很有趣。
结论
MCE 的作者 Mario Roy 为提供一个简单的 API 和出色的 文档 做了了不起的工作。使用像 MCE::Grep 这样的基本自动化模型开始是非常容易的,并且可以获得即时速度提升。然而,MCE 还有很多其他内容,如初始化和关闭例程、回调和序列。务必查看。
感谢
感谢 Jeff Thalhammer(《Stratopan》)推广这个模块。
您是否知道我们想要介绍的模块?如果是这样,我们很乐意听到您的意见!请将电子邮件发送到:perltricks.com@gmail.com。
本文最初发布在《PerlTricks.com》上。
标签
反馈
这篇文章有什么问题吗?请通过在 GitHub 上打开一个问题或拉取请求来帮助我们。
