




数据之慢船
Data::Dump::Tree旨在以更易读的方式呈现你的数据结构。它的实用性随着要显示的数据量而增长。
它不适合用来转储你永远不会再看的三变量,但它在呈现复杂数据、呈现你经常生成的内容以及呈现其他人将要读取的内容方面做得很好。
安装
你可以使用zef来安装它,它随Rakudo Star一起提供
zef install Data::Dump::Tree
Data::Dump::Tree 仓库有两个分支:release是zef安装的分支,master是主要开发分支。我选择在最新的Rakudo上进行开发,因为那里的错误已经被修复。我可能在不久的将来将发布分支更改为仅与Rakudo发布版本一起工作。有测试来检查模块的兼容性。
文章很少以寻求帮助开始,但我注意到当它们放在文章结尾时往往会被人忘记。有一些事情可以变得更好;如果你能帮忙,请帮一下!帮助列表在文章的结尾。
易读性原则
我的想法是使数据呈现如此简单和吸引人,以至于不需要手动从数据中提取相关信息。相反,通过过滤器呈现的数据既足够简单,对最终用户来说足够详细,对开发者来说也足够详细。
Data::Dump::Tree垂直显示数据,从而减少了文本/面积比。我尝试应用一些原则
- 限制文本与面积比;一个充满文本的屏幕是毫无用处的;文本的最大集中度具有很低的易读性
- 通过颜色、符号、字体大小和间距来对比渲染
- 简化 - 显示更少的数据,因为细节减少可以提高渲染的易读性
- 组织 - 转换或表格化的数据可以使数据更容易理解
- 关系 - 关系使数据具有上下文,我通过编号和着色渲染来实现这一点
- 交互式 - 你可以折叠或展开数据来管理渲染的复杂性
dd与ddt
毫无疑问,Rakudo内建的dd比我的ddt快得多,但以下是一些我认为由ddt呈现时更易读的例子。
[1..100]例子
use Data::Dump::Tree ;
dd [1..100] ;
ddt [1..100] ;dd的输出是一个紧凑性的例子——清晰且直接。

ddt垂直列出数据,所以我们得到一个长的渲染,如下所示(我截断了输出的前24行)

这是dd水平布局的明显优势,但让我们看看ddt能做什么,以及它何时可能比dd更易读。
ddt有一个:flat模式,可以更改渲染方向。诚然,渲染大型数据结构可能需要很长时间,但我发现那些大型数据结构在紧凑的渲染中是不可读的,所以我实际上只是在交换渲染时间与理解时间。
让我们将包含100个元素的数组以每列5个元素的方式呈现
use Data::Dump::Tree ;
ddt [1..100], :flat({1, 5, 10}) ;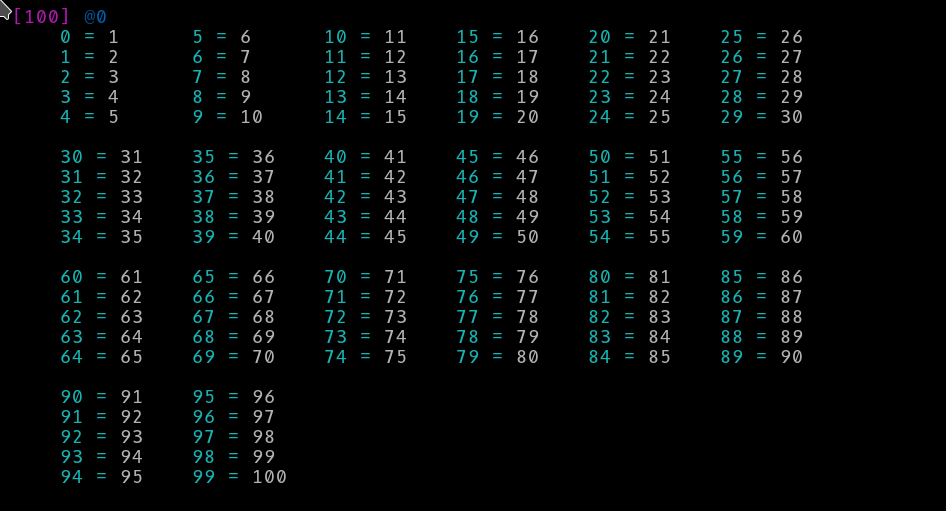
这稍微好一些,也更短,但所有这些索引都增加了一些噪音。或者它增加了噪音吗?我正在渲染的数据如此简单,以至于我不需要任何索引。如果数据没有排序怎么办?如果我想查看第50个索引的值怎么办?
这里是一个使用随机数据的示例。我还使用了10行的列而不是5行。你仍然觉得dd的输出更好吗?
use Data::Dump::Tree ;
dd True, [(1..100).pick: 100] ;
ddt True, [(1..100).pick: 100], :flat({1, 10, 10}) ;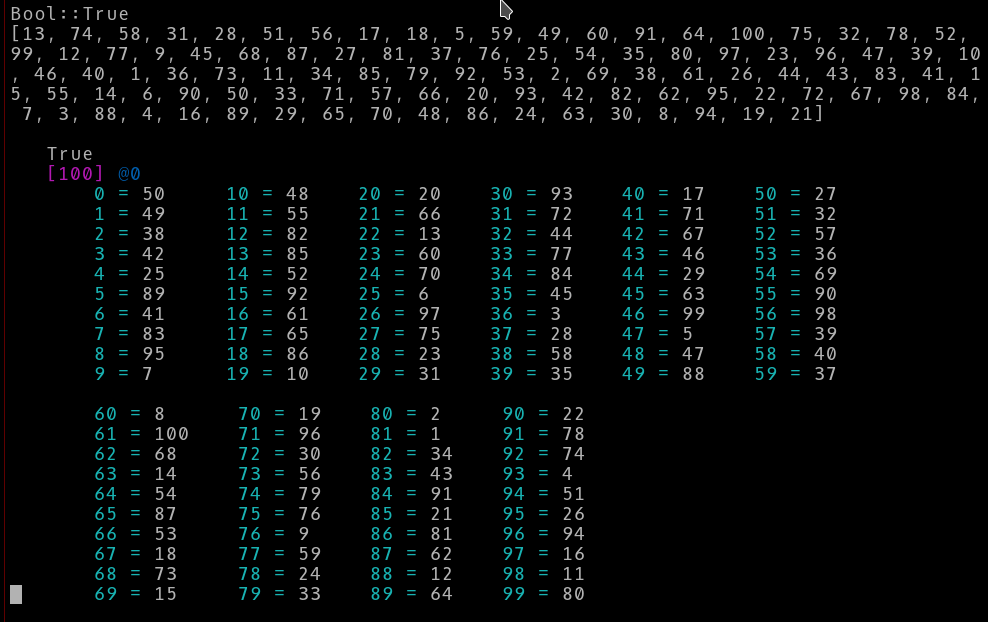
仍然不确信?300个随机整数怎么样?你能导航吗?
dd True, [(1..300).pick: 300] ;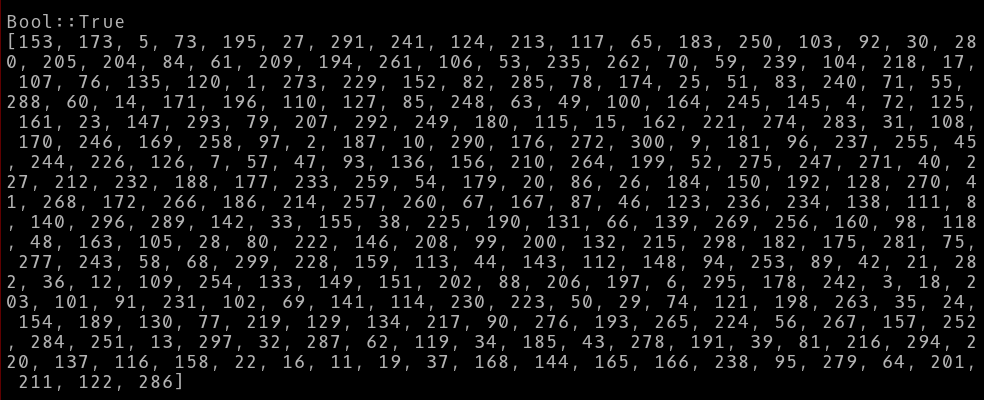
让我们让它更复杂一些。我想看到介于50到59之间的值。想象一下,我将一遍又一遍地展示这些数据,花几分钟改变数组显示方式对我来说是值得的
use Data::Dump::Tree ;
use Data::Dump::Tree::DescribeBaseObjects ; # for DVO
use Terminal::ANSIColor ;
role skinny
{
multi method get_elements (Array $a)
{
$a.list.map:
{
'',
'',
50 <= $_ < 60
?? DVO(color('bold red') ~ $_.fmt("%4d") ~ color('reset'))
!! DVO($_.fmt("%4d"))
}
}
}
ddt True, [(1..100).pick: 100], :flat({1, 10}), :does[skinny] ;
我可以显示一个表格或文本模式的图表。当我的数据具有非内置类型时,这甚至更好;我写一个处理程序,并将其交给ddt,所有实例都将按我的意愿渲染。我可以编写一个过滤器,并控制其他类型的显示方式,包括内置类型。Data::Dumper::Tree的目的是通过一些合理的默认值来控制数据的渲染方式。
项目仓库有更多示例。
内置类型与用户类型
尽管ddt处理了许多内置类型,但我还没有花时间查看一些类型。这些类型可能渲染错误或根本不渲染。如果你发现其中之一,请在GitHub上提出问题。如果你为该类型添加了处理程序,请提交一个拉取请求!你可以查看DescribeBaseObjects.pm以了解已经处理了哪些。
用户定义的类型以通用方式处理。如果它们定义了ddt_*方法,则将调用这些方法;否则将显示类型属性。《文档》有更多关于此的信息。
匹配
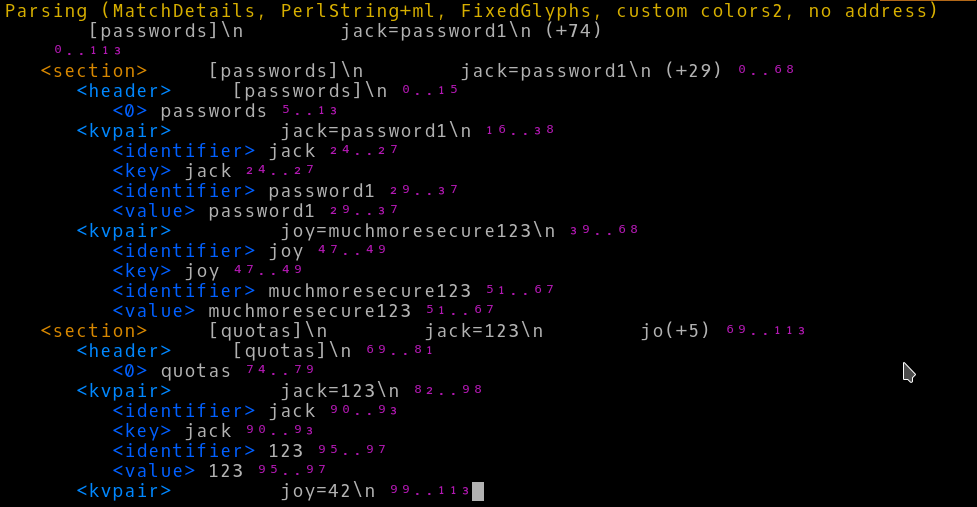
在审查Dumper中,brian指出ddt的输出对于匹配来说并不很有趣,他是对的。默认输出不仅没有帮助,甚至试图隐藏匹配的所有细节。这样做的原因是匹配对象中有些细节在渲染时通常没有用。
如果我想在数据渲染中看到匹配的细节呢?ddt有一个我可以使用的角色,这将使它与匹配一起工作时更有用。在examples/match.pl中有匹配角色使用示例,包括带有和没有额外过滤和着色的示例。
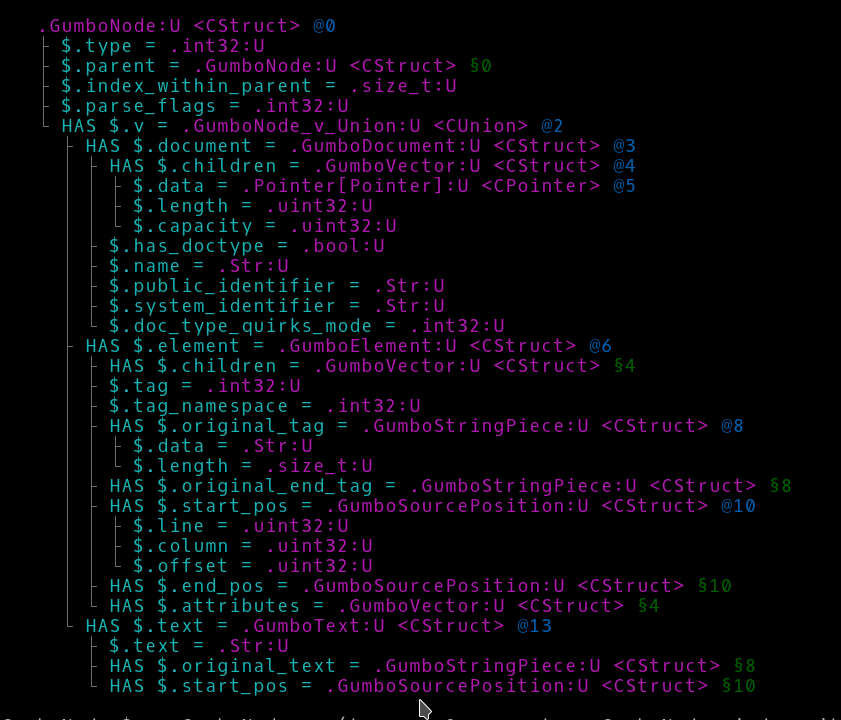
原生调用类型
看看examples/gumbo.pl。ddt可以处理Perl 6的原生调用支持。dd简单地显示类型GumboNode。ddt输出将其分解并注释数据结构中的C部分。
过滤
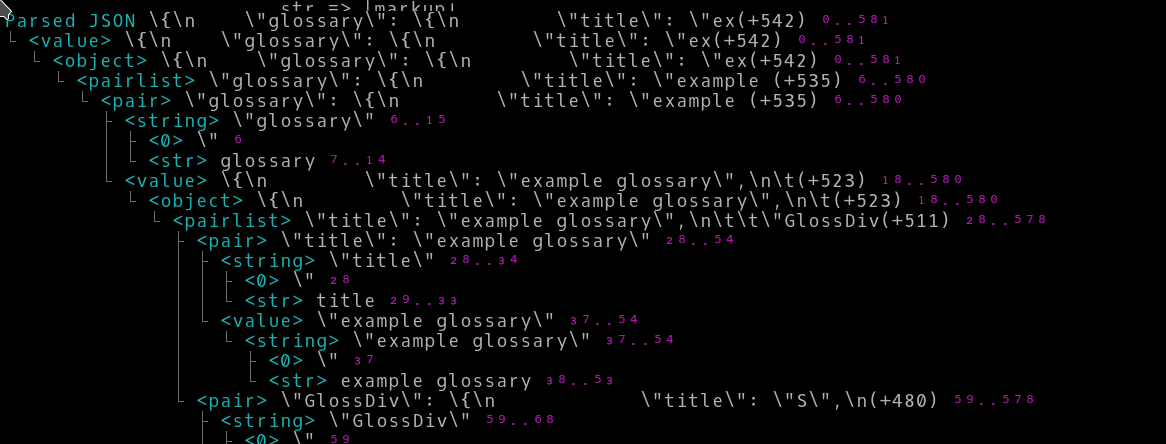
你在[1..100]示例中看到了处理程序的示例。这里是一个将过滤器应用于JSON数据结构解析的示例
sub header_filter
($dumper, \r, $s, ($depth, $path, $glyph, @renderings),
(\k, \b, \v, \f, \final, \want_address))
{
# simplifying the rendering
# <pair> with a value that has no sub elements can be
# displayed in a more compact way
if k eq "<pair>"
{
my %caps = $s.caps ;
if %caps<value>.caps[0][0].key eq 'string'
{
v = ls(~%caps<string>, 40) ~ ' => ' ~ ls(~%caps<value>, 40) ;
final = DDT_FINAL ;
}
}
# Below need no details
if k eq "<object>" | "<pairlist>" | "<array>" | '<arraylist>'
{
v = '' ;
f = '' ;
}
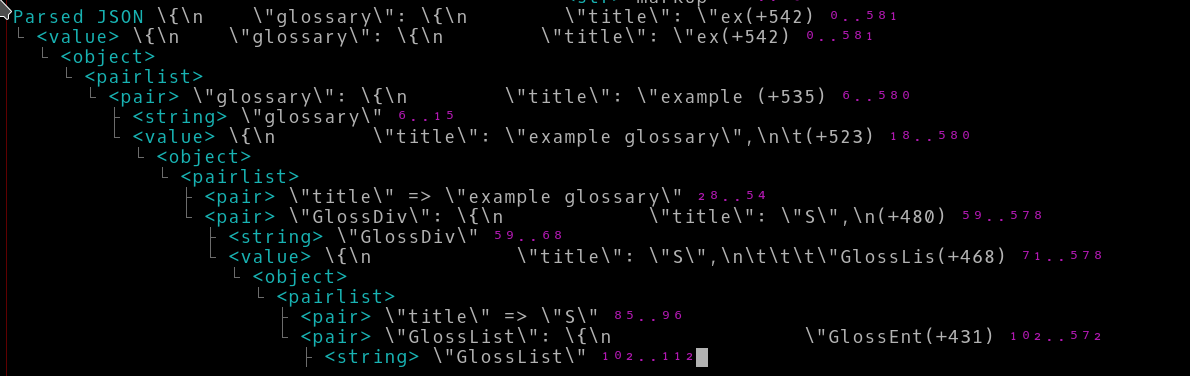
}应用上述过滤器后,显示的数据量减少了近三倍。以下是未过滤的输出
经过过滤的输出
折叠和共享

我可以通过使用:curses形容词在curses界面中显示渲染的数据结构
ddt $data_structure, :curses;我还可以将数据结构的渲染发送到另一个进程。这使得在没有杂乱显示的情况下更容易调试,例如。
ddt $data_structure, :remote;较少使用的选项
:nl在渲染的末尾添加一个空白行。:indent缩进整个渲染:!display_info、:!display_address、:!display_type这些从渲染中删除类型/地址,对于简单数据这可以提高可读性
获取帮助
我可以在#perl6 IRC频道找到,如果在GitHub上提出问题,我会收到邮件。我很乐意提供一般解释,并为新类型或您的类型编写处理程序/过滤器,特别是如果我可以在示例部分添加它。
伸出援手
有几个地方可能需要一些帮助。也许你可以着手解决这些问题之一
- 有一个DHTML渲染器需要一些关注。折叠容器没有视觉提示。搜索功能也需要润色。我不是网页专家,所以代码代表了我迄今为止的最佳努力
- 内置类型的
ddt支持可以扩展。这最好通过在你的脚本中进行测试并在类型不受支持时报告来实现 ddt运行缓慢;它做了很多事,但它可以做得更快。我尝试分析它,但没有取得很大进展。如果你精通Perl 6并且想看看代码,我将很乐意提供帮助- 你可以编写一个数据显示应用程序,该程序可以通过套接字接收数据结构并将其呈现给用户。它应该显示多个渲染并允许用户选择要显示的渲染。有点像日志查看器,但用于数据渲染
- 成为共同维护者,帮助维护此模块!
其他文章/链接
- Perl 6 Data::Dump::Tree 版本 1.5
- 在C端漫步,ddt,du du,du du …
- 给我看数据!
Data::Dump::Tree是我Perl 5模块Data::TreeDumper的延续
标签
反馈
这篇文章有什么问题吗?请在GitHub上打开一个问题或拉取请求以帮助我们
