




AXSP, 标签库和流水线
在本系列的第一篇文章中,我们看到了如何安装、配置和测试AxKit,并查看了一个简单的处理流水线。在这篇文章中,我们将看到如何编写一个简单的10行XSP标签库,并在流水线中使用它以及XSLT来构建动态页面,这样可以让系统架构师和编码人员从内容维护业务中解脱出来。在这个过程中,我们将讨论流水线处理模型,这是AxKit如此强大的原因。
首先,让我们了解一下AxKit世界的一些变化。
变化
Matt和公司已经发布了AxKit v1.5.1,1.5.2版本似乎也即将推出。1.5.1版本提供了一些改进和错误修复,特别是本文中讨论的XSP引擎。最大的新增功能是包含一系列演示页面,可用于测试和实验AxKit的功能,以及另一个模块来帮助编写标签库(Jorge Walter的SimpleTaglib,我们将在下一篇文章中探讨)。
还有一项发布策略的变化:主要的AxKit发行版(例如AxKit-1.5.1.tar.gz)将不再包含最小需求集;这些现在将捆绑在一个单独的tarball中。这项政策变化使得人们可以仅下载AxKit(例如在升级时),并承认AxKit是一个Apache项目,而需求不是。在需求tarball发布之前,本文附带的源tarball包含了所有这些(尽管它只在本地目录中安装它们,用于测试目的)。主要的AxKit tarball仍然包括所有核心AxKit模块。
XSP和标签库
我们在上一篇文章中提到了可扩展服务器页面和标签库;这次我们将进行更深入的探讨,并尝试了解如何以强大且有用的方式将XSP、标签库和XSLT结合起来。
快速标签库回顾:标签库是一组在XML命名空间中的XML标签,它们类似于条件语句或子程序调用。本质上,标签库是一种将逻辑和动态内容编码到页面中的方法,而无需在页面中包含原始“本地”代码(Perl、Java、COBOL;任何流行的Web编程语言);每个标签库提供一套相关服务,同一个XSP页面中可以使用多个标签库。
在我们的示例中,我们将构建一个“数据驱动”处理流水线(点击蓝色图标或箭头将带您到相关文档或本文的相应部分)
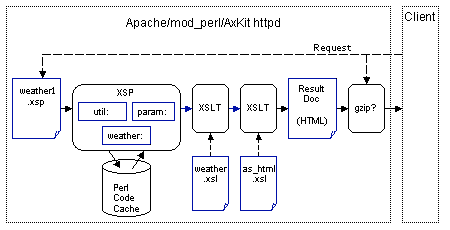 >
> ![]() 注意:像这样的小图标将与流水线每个部分的描述一起显示,该部分将被突出显示。点击这些图标将带您回到此图表。
注意:像这样的小图标将与流水线每个部分的描述一起显示,该部分将被突出显示。点击这些图标将带您回到此图表。
此流水线有五个阶段
- XSP文档(
weather1.xsp)以简单的XML格式定义了本页面所需的原始数据块(当前时间和天气读数), - XSP处理器将标签库应用于组装页面所需的原始数据,
- 第一个XSLT处理器和样式表(
weather.xsl)将原始数据格式化为可用的内容, - 第二个XSLT处理器和样式表(
as_html.xsl)负责布局并生成最终页面(“结果文档”),并且 - 如果客户端可以理解压缩内容,Gzip压缩器会自动压缩输出(即使较旧的浏览器害羞,不会宣布它能够处理gzip编码的内容)。
这种多遍扫描的方法模仿了实际应用中的方法;每个阶段都有其特定的目的,并且可以独立于其他阶段进行设计和测试。
在实际应用中,可能会有更多过滤器:我们的第二个XSLT过滤器可能被调整以构建没有任何“外观和感觉”的文档,并且可以使用额外的过滤器在布局完成后实现展示的“外观和感觉”。这将允许外观和感觉独立于布局进行更改。
我们称这种管道为“数据驱动”的管道,因为为管道提供文档定义了服务于页面所需的数据;它实际上并不包含任何内容。后续阶段添加内容并对其进行格式化。我们将在下一篇文章中查看“文档驱动”的管道,该管道将提供要服务的文档。
为什么使用管道?
AxKit使用的XML管道处理模型是一种强大方法,它为文档处理系统(如Web应用程序)带来了技术和社会的优势。
在社会方面,管道或装配线的概念足够简单,可以教授给非程序员并为他们所理解。一些面向HTML的工具(如CPAN上的一些工具)采用的方法并不完全是面向设计师的:它们依赖于面向程序员的友好概念,例如抽象数据结构、小型编程语言、“万能”页面以及面向对象技术,如方法调度。公平地说,一些设计师可以并确实学习了这些概念,而其他人有Perl实现者,他们以简单易懂的模式部署这些工具。
面向HTML的工具在处理像管道模型这样简单的东西时遇到困难,是因为HTML是一种表现语言,不利于描述数据结构或进行增量处理。增量处理的优势是阶段数可以根据应用程序和组织进行设计;在其他工具中,通常有一个或两个阶段的方案,其中第一阶段几乎完全在Perl编码者的领域(“准备数据”),第二阶段则一半在编码者的领域,一半在设计者的领域。
XML可以用来描述数据结构,也可以用来标记散文文档;这允许管道以灵活的方式混合数据和散文。每个处理阶段都是XML输入,XML输出(除了第一和最后一个,它们通常消费和生成其他格式)。然而,阶段并不限于仅处理XML:我们使用的标签库展示了阶段可以使用Perl代码(以及通过扩展,许多其他语言;请参阅Inline模块系列),外部库,以及几乎任何所需的非XML数据。My::WeatherTaglib不仅与Perl代码集成,还从远程站点请求数据。
作为阶段之间数据载体的XML的使用也允许每个阶段都可以进行调试和单元测试。在阶段之间传递的文档通常为了效率而作为内部数据结构传递而不是XML字符串,但它们可以被呈现(如本文中所示示例)并检查,既用于教学目的也用于调试目的。XML的统一外观和感觉(尽管有缺点),至少任何合格的Web设计师都可以轻松理解。
管道也是很有用的机制,因为各个阶段是在请求时选择的;可以选择不同的阶段来提供相同内容的不同视图。AxKit提供了几种强大的机制来配置管道,本文中使用的<xml-stylesheet ...>方法只是最简单的一种;未来的文章将探讨构建灵活管道的方法。
管道还区分了管理器(AxKit)和加工技术,这是一个有用的区分。这不仅允许您根据需要混合和匹配加工技术(AxKit配备了九种“语言”,或XML处理器类型,以及几个“提供商”,或数据源),而且还允许在新技术需要时将其纳入现有网站。
此外,像XML和XSLT这样的技术已经标准化,并且正在得到广泛的接受和支持。这意味着我们示例管道中的大多数,如果不是所有文档都可以放心地交给非Perl程序员,而不用担心他们会破坏代码。当他们确实破坏了它时,可以使用xsltproc等工具(由AxKit的XSLT处理器之一libxslt提供)来为设计师提供第一道防线,然后再请程序员。即使是标签库,尽管它们是非标准的,也能利用XML标准以(相对)安全的方式使逻辑和数据对非程序员可用。例如,这里有一个由ZVON.org提供的优秀在线教程。
请注意,XML和XSLT有其粗糙的地方;关键是您不需要了解XML规范的所有古怪之处,也不需要使用XSLT来处理在其中很痛苦的事情。我的意思是,您最后一次处理记法声明是什么时候?大多数XML的使用只使用了XML规范的一小部分,而在XSLT会使问题更加困难的地方,可以使用XSP、XPathScript和各种模式语言等其他工具。
适当阶段取决于应用程序的需求以及参与构建、运营和维护该组织的需求。在下一篇文章中,我们将检查一个“文档驱动”的管道和更适合这种方法的标签库,该标签库使用不同的阶段。
尽管如此,非XML和非管道解决方案仍将有其位置:XML和管道不是万能的。当与我合作的应用程序或组织不会从XML中受益时,我仍然使用其他解决方案。
httpd.conf:AxKit配置
在我们开始示例代码之前,让我们看一下AxKit配置。如果您愿意,可以跳到代码部分;否则,以下是我们将用于httpd.conf的配置。
## ## 初始化httpd以使用我们的“私有安装”库 ## PerlRequire startup.pl
##
## AxKit Configuration
##
PerlModule AxKit
<Directory /home/me/htdocs">
Options -All +Indexes +FollowSymLinks
# Tell mod_dir to translate / to /index.xml or /index.xsp
DirectoryIndex index.xml index.xsp
AddHandler axkit .xml .xsp
AxDebugLevel 10
AxGzipOutput Off
AxAddXSPTaglib AxKit::XSP::Util
AxAddXSPTaglib AxKit::XSP::Param
AxAddXSPTaglib My::WeatherTaglib
AxAddStyleMap application/x-xsp
Apache::AxKit::Language::XSP
AxAddStyleMap text/xsl
Apache::AxKit::Language::LibXSLT
</Directory>
这是上一篇文章中的相同配置——大多数指令和Apache和AxKit使用的处理模型都详细描述在那里。有两个指令被添加了粗体。我们示例的关键指令是AxAddXSPTaglib和AxAddStyleMap。
AxAddXSPTaglib指令加载了三个标签库:Kip Hampton的Util和Param标签库,以及我们自己的WeatherTaglib。Util将允许我们的示例获取系统时间;Param将允许它解析URL;而WeatherTaglib将允许我们获取该ZIP代码的当前天气状况。
两个AxAddStyleMap指令将一对MIME类型映射到一个XSP和一个XSLT处理器。我们的示例源文档将引用这些MIME类型来配置XSP和XSLT处理器的实例到处理管道中。
我们使用Apache::AxKit::Language::LibXSLT来执行XSLT转换,它底层使用GNOME项目的libxslt库。不同的XSLT引擎提供不同的功能集。如果您愿意,也可以使用Apache::AxKit::Language::Sablot进行XSLT工作。您甚至可以将它们分配给不同的MIME类型,在同一个管道中使用它们。
 My::WeatherTaglib
My::WeatherTaglib
这是一个使用CPAN上的Geo::Weather模块的taglib,它接受一个邮编,从weather.com获取一些天气观测数据,并将它们转换为XML。
package My::WeatherTaglib;
$NS = "http://slaysys.com/axkit_articles/weather/";
@EXPORT_TAGLIB = ( 'report($zip)' );
use strict;
use Apache::AxKit::Language::XSP::TaglibHelper;
use Geo::Weather;
sub report { Geo::Weather->new->get_weather( @_ ) }
1;
这个taglib使用Steve Willer的TaglibHelper(包含在AxKit中)来自动化处理XML的繁琐工作。因此,我们的示例taglib将大量功能浓缩到了几行Perl代码中。但请注意,这个模块背后还有很多事情在发生。
当在XSP页面中遇到像<weather:report zip="15206"/>这样的标签时,它将被转换为对report( "15206" )的调用,调用结果将被转换为XML,并替换XSP输出文档中的原始标签。
$NS变量设置了taglib的命名空间URI;这配置XSP将命名空间http://slaysys.com/axkit_articles/weather/内的所有元素都指向My::WeatherTaglib,就像我们稍后将看到的那样。
在XSP页面中使用时,由taglib提供的所有XML元素都将有一个命名空间前缀。例如,前缀
weather:映射到下面XSP页面中My::WeatherTaglib的命名空间。这个前缀不是由taglib确定的——我们可以选择另一个;本节假设使用前缀weather:是为了清晰起见。
@EXPORT_TAGLIB指定了将哪些函数作为此命名空间中的元素导出以及它们接受的参数(有关详细信息,请参阅文档)。report($zip)导出规范导出了一个像<weather:report zip="..."/>或
<weather:report>
<weather:zip>15206</weather:zip>
</weather:report>
@TAGLIB_EXPORT定义中的“report”和“zip”这两个词用于确定taglib元素和属性名称;定义中参数的顺序决定了它们传递给函数的顺序。在调用taglib时,XML可以以任何顺序在XML中指定参数。它们指定的名称默认情况下对Perl代码不重要或不可见(有关如何接受XML树的信息,请参阅*argument函数规范)。
我们剩下的工作是为taglib编写“主体”,即通过use()语句使用Geo::Weather并编写report()子程序。
TaglibHelper提供了两个主要便利之处。第一个是将Perl子程序焊接(通过@EXPORT_TAGLIB定义)到XML标签上。第二个是将report()返回的Perl数据结构转换为如
{
city => "Pittsburgh",
state => "PA",
cond => "Sunny",
temp => 76,
pic => "http://image.weather.com/web/common/wxicons/52/26.gif",
url => "http://www.weather.com/search/search?where=15206",
...
}
这样的良好平衡的XML。
<city>Pittsburgh</city>
<state>PA</state>
<cond>Sunny</cond>
<temp>76</temp>
<pic>http://image.weather.com/web/common/wxicons/52/26.gif</pic>
<url>http://www.weather.com/search/search?where=15206</url>
...
TaglibHelper允许返回普通的字符串、数据结构和良好平衡的XML字符串。通过编写一个单行子程序,它返回一个Perl数据结构,我们编写了一个无需Perl专业知识即可使用的taglib(任何XHTML爱好者都可以使用他们喜欢的XML、HTML或文本编辑器安全地使用它),并且它可以用于为XML-RPC-like应用程序提供“数据”响应或为人类消费提供“文本”文档。
Perl附带的Data::Dumper模块是一种很好的方式,可以查看请求中漂浮的数据结构。在AxKit中运行时,一个简单的
warn Dumper( $foo );就会将$foo所引用的数据结构输出到Apache的错误日志。
从taglib输出的XML将替换结果文档中的原始标签。在我们的情况下,替换后的XML本身并不太有用,它只是看起来有点像XML的数据。对于Perl专家来说,将数据结构表示为XML可能显得有些笨拙,但如果您想将Perl代码安全地从关键路径中移除,并允许其他人使用XML工具处理数据,这会非常有帮助。
我们XSP处理器生成的“数据文档”将在后续的处理阶段升级为可供客户端显示的内容;我们的XSP页面既不知道也不关心它将如何被展示。在这里将原始数据以XML形式导出是为了展示如何通过允许网站设计师和内容作者进行操作,从而使Perl专家在内容开发的关键路径中解脱出来。
从XSP页面中输出结构化数据只是其中一种方法。Taglib可以根据特定的应用程序返回“最佳匹配”的结果,无论是原始数据、内容片段还是整篇文章。
Cocoon,AxKit主要受其启发的系统,使用不同的方法来编写taglib。AxKit也支持这种方法,但它通常比较繁琐,所以将在下一篇文章中探讨。我们还将探讨Jorge Walter的新的SimpleTaglib模块,它比我们这里探讨的TaglibHelper模块更新、更灵活,但不太便携。
weather1.xsp:使用My::WeatherTaglib
这是一个页面(weather1.xsp),它使用了My::WeatherTaglib和我们在上一篇文章中使用的“标准”XSP util taglib。
<?xml-stylesheet href="NULL" type="application/x-xsp"?>
<?xml-stylesheet href="weather.xsl" type="text/xsl" ?>
<?xml-stylesheet href="as_html.xsl" type="text/xsl" ?>
<xsp:page
xmlns:xsp="https://apache.ac.cn/1999/XSP/Core"
xmlns:util="https://apache.ac.cn/xsp/util/v1"
xmlns:param="http://axkit.org/NS/xsp/param/v1"
xmlns:weather="http://slaysys.com/axkit_articles/weather/"
>
<data>
<title><a name="title"/>My weather report</title>
<time>
<util:time format="%H:%M:%S" />
</time>
<weather>
<weather:report>
<!-- Get the ?zip=12345 from the URI and pass it
to the weather:report tag as a parameter -->
<weather:zip><param:zip/></weather:zip>
</weather:report>
</weather>
</data>
</xsp:page>
当请求weather1.xsp时,AxKit解析<?xml-stylesheet ...?>处理指令,并使用AxAddStyleMap指令构建如上图所示的处理器链。

XSP处理器是管道中的第一个处理器。在解析页面时,它会将所有以util:、param:或weather:前缀开头的元素发送到Util、Param和WeatherTaglib taglib。这种映射由xmlns:...属性和每个taglib实现中硬编码的命名空间URI定义(参见My::WeatherTaglib中的$NS变量)。
在这个页面中,<util:time>元素导致调用Util的get_date()函数,并将format=属性的值作为参数传入。由get_date()返回的字符串被转换为XML并输出,代替输出页面中的<util:time>元素。这展示了如何向taglib传递简单的常量参数。
我们对<weather:report>元素的处理稍微复杂一些:这个结构从请求URI的查询字符串(或表单字段)中获取zip参数,并将其作为$zip参数传递给WeatherTaglib的report()函数。感谢Kip Hampton在此过程中使用AxKit::XSP::Param的帮助。
因为我们将AxDebugLevel设置为10,您可以在编译后的weather1.xsp版本中看到这些调用;生成的Perl代码被写入Apache的错误日志——通常是$SERVER_ROOT/logs/error_log。
<title>元素中的<a name="title"/>是为了在处理链中稍后展示一个功能而添加的权宜之计。庆幸它不是那个令人讨厌的<blink>标签!
从XSP处理器输出的XML文档,并将其馈送到第一个XSLT处理器,其外观如下(加粗表示标签库输出):
<?xml version="1.0" encoding="UTF-8"?>
<data>
<title><a name="title"/>My weather report</title>
<time>16:11:55</time>
<weather>
<state>PA</state>
<heat>N/A</heat>
<page>/search/search?where=15206</page>
<wind>From the Southwest at 10</wind>
<city>Pittsburgh</city>
<temp>76</temp>
<cond>Sunny</cond>
<uv>2</uv>
<visb>Unlimited</visb>
<url>http://www.weather.com/search/search?where=15206</url>
<dewp>53</dewp>
<zip>15206</zip>
<baro>29.75</baro>
<pic>http://image.weather.com/web/common/wxicons/52/26.gif</pic>
<humi>31</humi>
</weather>
</data>
这些数据在很大程度上是表现无关的——请忽略以美国为中心的温度刻度——可以根据需要对其进行样式化。
要生成此中间文档,只需注释掉除了第一个
<?xml-stylesheet ... ?>处理指令之外的所有内容,并按照如下请求页面$ lynx -source localhost:8080/02/weather1.xsp?zip=15206 | xmllint --format -
xmllint与AxKit所用的GNOMDElibxsml库一起安装。当我们在更多动态的方式中介绍如何构建比使用这些陈旧的xml-stylesheet PIs更灵活的管道时,这些技术可以用来允许通过改变请求URI来显示中间文档。
weather.xsl:将数据转换为内容
以下是我们将XSP处理器输出的数据文档转换为更易读文本的方法。如上面所述,我们采用两步方法来模拟将我们的数据转换为内容块的过程,并在第一步中将其作为(可重复使用的)步骤,然后在第二步中布局HTML。
weather.xsl是一个XSLT样式表,它使用多个模板将XSP输出转换为更易读的格式。
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
<xsl:template match="/data/time">
<time>Hi! It's <xsl:value-of select="/data/time" /></time>
</xsl:template>
<xsl:template match="/data/weather">
<weather>The weather in
<xsl:value-of select="/data/weather/city" />,
<xsl:value-of select="/data/weather/state"/> is
<xsl:value-of select="/data/weather/cond" /> and
<xsl:value-of select="/data/weather/temp" />F
(courtesy of <a href="{/data/weather/url}">The
Weather Channel</a>).
</weather>
</xsl:template>
<xsl:template match="@*|node()">
<!-- Copy the rest of the doc verbatim -->
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
这是由管道中的第一个XSLT处理器应用的。
这里有趣的是,我们正在使用两个模板(以粗体显示)来处理源XML的不同部分。这些模板将时间和天气数据“摘要”成可展示的块,并且作为副作用,丢弃天气报告中未使用的数据。
第三个模板只是将剩余内容传递通过(XSLT有一些令人讨厌的特性,其中之一是它需要一些复杂的代码才能简单地将内容“原样”传递)。然而,这是一个模板——实际上是从XSLT规范中来的——并且不需要干扰设计师创建此样式表中我们实际想要的两个模板。
另一个令人讨厌的特性是XSLT构造看起来与模板本身非常相似。这违反了语言设计原则“不同的事情应该看起来不同”,这是Perl和许多其他语言中使用的。可以通过使用XSLT感知编辑器或语法高亮来缓解这种差异,以使XSLT语句和“有效负载”XML之间的差异更加清晰。
第一个XSLT处理器的输出如下(模板输出以粗体显示):
<?xml version="1.0"?>
<data>
<title><a name="title"/>My weather report</title>
<time>Hi! It's 16:50:36</time>
<weather>The weather in
Pittsburgh,
PA is
Sunny and
76F
(courtesy of <a href="http://www.weather.com/search/search?where=15206">The
Weather Channel</a>)
</weather>
</data>
现在我们有一组可以放置在网页上的块。此技术可以用来以可重复使用的方式构建侧边栏、报纸标题、摘要、联系列表、导航提示、链接、菜单等。
as_html.xsl:布局页面
在这个示例中的最后一步是将我们构建的块插入到使用as_html.xsl样式表的HTML页面中。
<xsl:stylesheet
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
version="1.0">
<xsl:output method="html" />
<xsl:template match="/">
<html>
<head>
<title><xsl:value-of select="/data/title" /></title>
</head>
<body>
<h1><xsl:copy-of select="/data/title/node()" /></h1>
<p ><xsl:copy-of select="/data/time/node()" /></p>
<p ><xsl:copy-of select="/data/weather/node()" /></p>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
生成最终HTML
<html>
<head>
<meta content="text/html; charset=UTF-8" http-equiv="Content-Type">
<title>My weather report</title>
</head>
<body>
<h1><a name="title"/>My weather report</h1>
<p>Hi! It's 17:05:08</p>
<p>The weather in
Pittsburgh,
PA is
Sunny and
76F
(courtesy of <a href="http://www.weather.com/search/search?where=15206">The
Weather Channel</a>).
</p>
</body>
</html>
在结果文档中使用数据文档中的 /data/title 两次是分离原始数据生成和最终呈现好处的一个小例子。在 <title> 元素中,我们使用 xsl:value-of,它只返回文本内容;在 <h1> 元素中,我们使用 xsl:copy-of,它复制标签和文本。这使得标题可以包含我们在一个地方剥离并在另一个地方使用的标记。
这类似于在真实应用中经常遇到的情况,例如菜单、按钮、位置提示符(“首页 >> 文章 >> Foo” 等)以及相关页面的链接通常出现在多个地方。这样的小部件是布局页面按需放置的理想“块”。
这只是一个“最终渲染”阶段的例子;可以使用不同的过滤器来提供不同的格式。例如,我们可以使用 XSLT 来提供 XML、XHTML 和/或纯文本版本,或者我们可以使用 AxKit 特定的处理器 XPathScript 来转换成 RTF、nroff 和其他 XML 较难提供的文档格式。
AxKit 通过在两个阶段之间直接传递
libxslt使用的内部表示来优化这个两阶段的 XSLT 处理。这意味着一个阶段的输出直接传递到下一个阶段,而无需重新解析。
将 weather1.xsp 与现实世界相关联
如果你仔细看 My::WeatherTaglib 中的代码,你可以想象使用 DBI 查询而不是让 Geo::Weather 查询远程网站(在这篇文章中,使用 Geo::Weather 而不是 DBI 来保持示例代码和存档相对简单)。
将查询和其他业务逻辑写入到标签库中有几个主要优势
- XML 标签库 API 为查询提供了一个面向设计师的界面,允许非 Perl 熟悉的人使用他们喜欢的工具调整或维护 XSP 页面,希望让你摆脱“请调整查询参数”的关键路径。
- 由于标签库 API 是 XML,标准 XML 编辑器可以捕获基本语法错误,而无需调用标签库维护者。
- 模式验证器和 XSLT 工具也可以用来允许设计师在烦扰标签库维护者之前检查高级语法。
- 可以使用 Perl 调整查询参数和输出,这使得“高级”XML 接口更简单,更不容易出错。
- 输出是 XML,因此可以使用其他 XML 处理器来增强内容和样式。这允许,例如,XSLT 熟练的设计师在不学习或甚至看到(可能破坏)任何 Perl 代码或新语言的情况下(如大多数 HTML 模板解决方案所要求的)进行工作。
- 使用 XSP 生成格式不正确的 XML 很困难:良好的 XSP 通常生成良好的输出。
- 查询与源 XML 解耦,因此可以在不接触 XSP 页面的情况下维护。
- 标签库可以像单元测试一样进行测试,而嵌入式代码则不能。
- 标签库可以是现有模块的包装器,因此相同的 Perl 代码可以由 web 前端和任何其他需要它们的脚本或工具共享。
- 标签库的插件性质允许使用许多公共和私有 XSP 标签库设施进行快速原型设计。CPAN 的 充满了它们。
- 除了上面演示的两个“功能”标签之外,你还可以编写“条件”标签,以控制 XSP 页面的一个块是否包含;这给了你响应用户偏好或权限的能力,例如。
DBI模块允许您使用几乎任何数据库,从逗号分隔值文件(甚至支持SQL JOIN)到MySQL、PostgreSQL、Oracle等,并返回Perl数据结构,这些数据结构简直就是从taglib函数返回并转换为XML的理想选择。
对于快速的单次页面和原型,ESQL taglib允许您在XSP页面中直接嵌入SQL。这不是推荐的做法,因为它对于高流量站点来说效率不足(每次都会重建数据库连接),并且将编程代码与XML混合会导致一些难以阅读且难以维护的页面,但这对单次页面和原型来说是个好选择。
帮助与感谢
如果遇到问题,可以查看上次我们列出的一些有用的资源。
感谢Kip Hampton、Jeremy Mates和Martin Oldfield,他们的彻底审查,尽管我相信我还是设法绕过了他们的一些漏洞。AxKit以及它所使用的许多Perl模块主要是由Matt Sergeant编写的,并得到了这些好人以及其他人的大量贡献,所以也要感谢所有的贡献者。
版权所有2002,罗伯特·巴里·斯莱梅克二世,保留所有权利。
标签
反馈
这篇文章有什么问题吗?请通过在GitHub上打开一个issue或pull request来帮助我们。
