




使用DFA::Simple构建有限状态机
我将一些文章从MS Word手动转换为HTML。我经常使用项目符号概要,因此创建嵌套子列表的列表需要做很多工作。打开和关闭许多<ul>和<li>标签后,我意识到我希望自动化这项任务。
使用我的文本编辑器的过滤器很容易,我已经用Perl编写了几个来加快HTML格式化的速度。我决定创建一个过滤器来处理这个烦人的任务。经过一番思考,我认为所涉及的逻辑足够复杂,可以使用有限状态机(FSM)来保持事情条理清晰。
大型程序总是需要思考和计划,而大多数小型程序可以即兴创作。有时我会遇到一些小问题,它们具有足够的复杂性,我知道“即兴创作”很快就会变成“不够快、非常混乱、可能错误。”有限状态机可以帮助干净、正确地解决这些复杂问题。
有好几次我想使用FSM,但因为缺乏良好的起始框架而没有这样做。我会用其他方式做,或者手动使用循环、嵌套if语句和状态变量来编写FSM。这种方法既繁琐又不令人满意。
我知道肯定有一些Perl模块实现了FSM,决定是时候把这个工具添加到我的工具箱中。
什么是有限状态机?
有限状态机是一组状态,其中一个是起始状态。每个状态都有一个到其他状态的转换集,这些转换基于下一个输入令牌。转换有一个条件和动作。如果条件得到满足,FSM执行动作然后进入新状态。这个循环一直重复,直到达到最终状态。
有限状态机在计算理论中非常重要。一篇关于有限状态机的维基百科文章探讨了计算机科学的方面。FSM很有价值,因为可以精确地确定它们可以和不能解决的问题。要解决一类新问题,添加功能以创建相关机器。反过来,你可以通过所需解决该问题的机器类型来表征问题。最终,你会达到图灵机,这是最理论上的完整计算设备。它是一个有限状态机,附加到一个具有潜在无限容量的磁带上。
对FSM的正式和高度抽象的计算机科学方法并没有暗示它们在解决实际问题方面的有用性。
气泡图
图1显示了有限状态机的各个部分。圆圈代表状态。双圆圈表示起始状态。弧代表从一个状态到另一个状态的转换。每个弧的标签是一个条件。斜杠分隔动作。
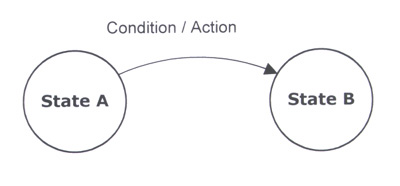 图1. 有限状态机元素。
图1. 有限状态机元素。
我喜欢FSM,因为它们是图形的。我可以拿起笔,勾勒出问题的解决方案。气泡图帮助我以逻辑和组织的方式看到状态和输入条件的组合。
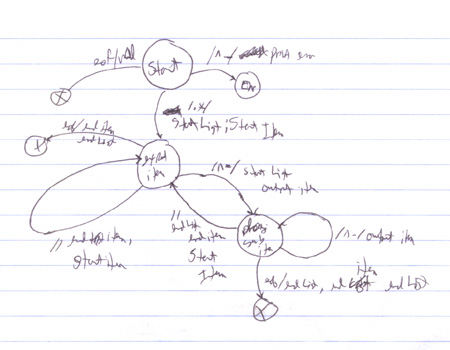 图2. 初始草图。
图2. 初始草图。
图2是我为HTML列表问题绘制的初始图。这个图最终出现了一个遗漏——它没有处理空白行。在发现这个错误后,很容易确保在每个状态下都考虑空白行。
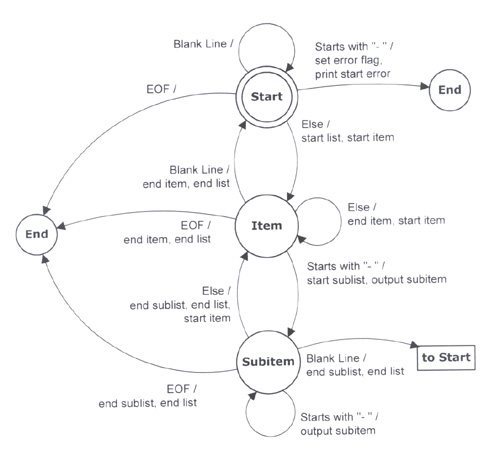 图3. 最终图。
图3. 最终图。
图3是最终FSM的正式图,包括空白行处理,专为这篇文章准备。通常,我绝不会为这么小的问题做这么详尽的工作。你可以看到,这是一种向他人传达解决方案的绝佳方式。
查看DFA::Simple
我还没有找到做某事的Perl模块,却一无所获。这绝对是我最喜欢的Perl特性。
我寻找现有的FSM模块,找到了DFA::Command和DFA::Simple。DFA::Command看起来不错,但超出了我的需求。(顺便说一下,最简单的FSM也是一个“确定性有限自动机”,所以模块名称中的DFA。)
DFA::Simple中的“simple”听起来很有希望,但该模块的文档很糟糕。示例程序难以理解,并且不处理文件输入。在现实世界中使用该模块留给读者练习:文档没有提及错误处理和文件结束条件。
虽然FSM最初以圆形和弧线开始,但最终会变成状态和转换的表格。我对这些包如何创建这些表格很感兴趣。对我来说,拥有干净、易于查看的代码非常重要。我可能是将来必须更改它的人!
我非常不满意DFA::Simple以位置依赖的方式定义其示例FSM。所定义的状态取决于其在源代码中的文本位置。它在表中使用数字常量作为状态ID,你必须与任何更改同步。注释表明你认为你正在处理哪个状态号,但当你添加、删除和移动状态时,它们很容易不同步。
为了澄清,我看到这个
my $states = [
# State 0
[ ...jump to state 2... ],
# State 1
[ ...jump to state 0... ],
# State 2
[ ...jump to state 1... ],
# ...
];
但我希望看到这个
my %states;
$states{stStart} = [ ...jump to stSubitem... ];
$states{stItem} = [ ...jump to stStart... ];
$states{stSubitem} = [ ...jump to stItem... ];
# ...
这是一个大问题。我遇到了足够多的由位置依赖性引起的错误,以至于我拒绝考虑使用这段代码。我几乎决定写自己的模块,但首先又回过头去看看DFA::Simple,看看是否有办法让它工作。
我意识到FSM使用符号常量进行状态定义。使用这些符号常量的数组引用将提供我要求的自文档化和可维护的方法。我很容易开发出一种处理输入的方法(处理错误和EOF),这在大多数情况下都适用。我把它组合起来,试了一下,它真的工作了!
输入和输出
输入是从复制MS Word文档并将其粘贴到我的文本编辑器中得到的。我的项目符号大纲看起来像这样
o Major bullet points
- each line is a point
- a leading "o " is removed
o Minor bullet points
- indicated by a leading "- "
- may not start a list
- only one level of minor points is supported
o Future enhancements
- numbering of points
- handling of paragraphs
o Start a new group of points
- a blank line indicates end of old group
- old group is closed, new one opened
这个大纲实际上记录了程序的关键功能。
正确嵌套的HTML列表必须完全位于父列表项内。这使得过滤器变得足够复杂,以至于我想使用有限状态机。当你打开顶级列表元素时,你必须等待下一个输入以确定你应该关闭它还是开始一个子列表。当你查看输入时,你必须知道你是否有一个待处理的打开列表项。当前状态和输入确定接下来要做什么,这与有限状态机模型完全吻合。
输出片段
<ul>
<li>Major bullet points
<ul>
<li>Each line is a point</li>
<li>A leading "o " is removed</li>
</ul>
</li>
...
</ul>
作为一个非HTML专家,我最初试图在我的两个更高级列表元素之间插入我的子列表。页面渲染正确,但无法验证,揭示了错误并启动了这个项目。
机器的各个部分
构建机器的第一步是决定如何以符号形式而不是数值形式表示状态名称。自然的选择是constant祈使句。
use constant {
stStart => 0,
stItem => 1,
stSubItem => 2,
stEnd => 3,
};
我将机器定义为两个数组。第一个是@actions,定义进入和退出状态时应该做什么。您可能用它来初始化数据结构并在进入时保存它,或者在退出时释放资源。
@actions的每个元素都是一个包含两个元素的数组。第一个是进入动作,第二个是退出动作。我的程序在进入时记录一条消息,并保留退出动作未定义。
my @actions;
# log entry into each state for debugging
$actions[stStart] = [sub{print LOG "Enter Start\n";} ];
$actions[stItem] = [sub{print LOG "Enter Item\n";} ];
$actions[stSubItem] = [sub{print LOG "Enter SubItem\n";}];
$actions[stEnd] = [sub{print LOG "Enter End\n";} ];
@states数组的每个元素是状态转换数组。转换有三个元素:新状态;测试条件;和动作。条件是一个返回真或假的子例程,或者返回undef,它总是成功。
机器按顺序测试当前状态的转换,直到条件返回真或未定义。然后它执行动作并进入新状态。如果新状态与旧状态不同,将执行相应的退出和进入动作。
就像嵌套的if语句中的最后一条else一样,考虑在转换的末尾放置一个undef。至少,记录一个“不可能发生”的错误消息,以捕获逻辑中的漏洞以及由未来更改引起的漏洞。
以下是一个状态转换数组
my @states;
# Next State, Test, Action
$states[stSubItem] = [
[stEnd, sub{$done}, sub{end_sublist; end_list} ],
[stSubItem, sub{/^-\s/}, sub{output_subitem} ],
[stStart, sub{/^$/}, sub{end_sublist; end_list} ],
[stItem, undef, sub{end_sublist; start_item}],
];
这个例子在两个表中都使用了状态ID的符号常量。状态的数值无关紧要。我遵循了惯例,将状态连续编号从零开始,但使用随机状态编号测试了程序。它工作得很好。
这比DFA::Simple中示例FSM的定义要好得多。现在添加、删除和重新排列状态不会引入位置相关的错误。
最终组装
机器的各个部分已经建成。组装它们很简单
use DFA::Simple
my $fsm = new DFA::Simple \@actions, \@states;
$fsm->State(stStart);
这使用对@actions和@states数组的引用创建一个新的DFA::Simple对象。State方法检索或设置机器的状态,根据需要调用进入和退出例程。这里,调用设置了初始状态。
让机器运转起来
这个项目的重大目标是开发一个快速开发FSM的框架,重点在于过滤器。我想开发一种处理文件输入和处理错误的方法,该方法适用于未来的项目。
这个循环实现了这一点
while (<>) {
chomp;
# log input line for debugging
print LOG "Input <$_>\n";
# trim input and get rid of leading "o "
s/^\s+//;
s/\s+$//;
s/^o\s+//;
# process this line of input
$fsm->Check_For_NextState();
# get out if an error occurred
last if $error;
}
while (<>)循环是过滤器的标准。应用程序根据需要清理输入。在这种情况下,它删除每行的空白字符并删除一些文本项目符号字符。
日志消息用于初始调试。这,加上新状态消息,清楚地说明了正在发生的事情。
最重要的语句是$fsm->Check_For_NextState();,它执行主要工作——扫描当前状态的转换表以查看下一步该做什么。
如果FSM发现错误,它必须能够提前退出。这需要使用全局$error开关。它最初是假的。如果$error为真,则程序结束并返回$error的值。
文件结束处理也使用全局开关$done。它最初是假的,当程序耗尽标准输入时变为真。运行最后一个循环,以便机器有机会清理。检查EOF的转换条件可以简单地返回$done。
以下是文件结束代码
unless ($error) {
# finish up
$done = 1;
$fsm->Check_For_NextState();
}
该程序不支持提前正常终止。您可以进入一个没有转换的状态,程序将读取(但忽略)任何剩余的输入。然而,没有方法在不设置 $error 的情况下避免读取所有输入。您可以通过添加一个 $exit 开关并类似于 $error 的方式处理它来实现提前退出。
对于过滤器来说,这个程序是面向行的。许多状态机一次读取一个字符的输入:例如,词法分析器和正则表达式解析器。这个程序可以很容易地改为处理字符输入。
动作例程
现在,机器正在平稳运行,它需要做些什么。这就是动作的目的。在我程序中的动作是有限状态机的典型。它们调用形成构建具有子列表的列表的迷你语言的子例程。子例程非常简单,但按正确的顺序运行它们就能完成任务。
因此,这种方法将复杂问题分解为更小的部分,每个部分都很容易解决。这就是编程的全部内容。
结论
下次您遇到这种复杂的小问题时,尝试使用气泡图绘制解决方案,并使用 DFA::Simple 实现它。您将为您的工具箱添加一个极好的新工具。
资源
标签
反馈
这篇文章有什么问题吗?请在 GitHub 上打开一个问题或拉取请求来帮助我们。
