




一个AxKit图片库
AxKit不仅限于处理纯XML数据。从本文开始,我们将通过开发一个图像浏览器来处理和围绕非XML数据,该浏览器可以处理两种非XML数据:由操作系统调用(文件名和统计信息)构建的目录列表和图像文件。此外,它将由小型模块构建,您可以根据需要对其进行调整或用于其他地方,例如缩略图生成器或HTML表格包装器。
完成这些后,到那时,我们将希望得到一个应用程序,
- 提供在包含图像的目录树中的导航,
- 显示带缩略图的图像库,
- 忽略非图像文件,
- 允许您定义并展示有关每张图像的定制信息(“元数据”),
- 允许您查看带有或不带有元数据的完整图像,
- 使用非AxKit mod_perl处理程序在运行时生成缩略图图像,并且
- 允许您在浏览器中编辑元数据信息
这个功能列表应该使我们能够构建一个“现实世界”的应用程序(而不是我们之前讨论的天气示例),并且希望它也是一个有用的应用程序。以下是本文和下一篇文章创建的页面截图
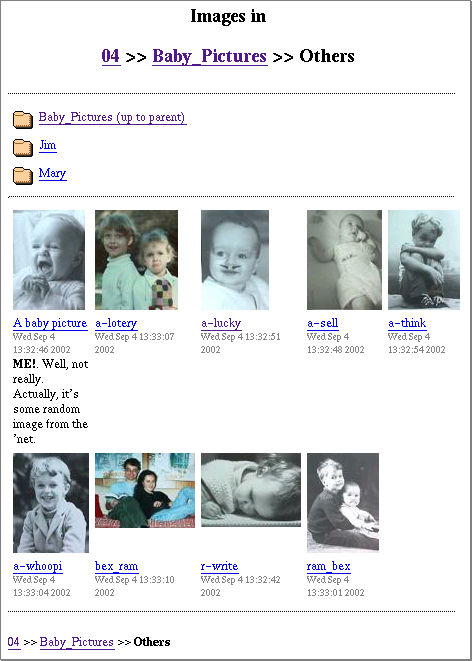
该页面有四个部分
- 标题:告诉您所在位置并提供向上导航目录树的方法。
- 文件夹:链接到父目录和任何子文件夹(Jim和Mary)。
- 图像:为每张图像提供缩略图和标题区域。单击图像或图像标题可转到完整尺寸的变体。
- 页脚:在滚动通过大量图像页面后,可以通过它返回目录树。
我们将在此文中实现(最具挑战性的)第三部分,在下一篇文章中实现其他部分。
如果您想回顾AxKit和Apache配置的基本知识,那么以下是本系列的先前文章
将非XML数据作为XML处理
在AxKit中实际处理非XML数据的最简单方法是将它转换为XML,并将其提供给AxKit。AxKit本身在其新的目录处理功能中也采用这种方法——多亏了Matt Sergeant和Jörg Walters,AxKit现在可以扫描目录并构建包含所有数据的XML文档。这很像原生Apache在提供HTML目录列表时的行为,但它允许您对其进行过滤。本文的主要内容是关于过滤该目录列表以创建缩略图图像库或校样。
本系列文章 介绍AxKit XSP、Taglibs和Pipeline Taglib TMTOWTDI |
在这种情况下,我们将使用AxKit标准工具包中相对较新的功能——SAX Machines,这是由Kip Hampton集成到AxKit中的。(免责声明:《XML::SAX::Machines》是我编写的一个模块。)我们将创建的SAX机器将是一个带有几个过滤器的直接管道,类似于AxKit使用的管道。这个管道将解析目录列表,并为易于显示而生成分段为行的图像列表。我们不会深入探讨SAX或SAX机器的细节,除了将三个构建块组合在一起;所有繁琐的细节都由其他模块为我们处理。如果您对细节感兴趣,请参阅Kip在《XML.com》上发表的“介绍XML::SAX::Machines”一文的第一部分和第二部分。
SAX机器构建好我们的图像列表后,将使用XSLT将来自独立XML文件(如图像标题和注释)的元数据合并,并将结果格式化以供浏览器使用。生成的页面看起来像
管理非XML数据(图像)
另一方面,将原始图像数据XML化没有意义(尽管像SVG(在XML.com的Sacre SVG文章中介绍)和dia文件这样的数据是自然的适合),因此我们将利用AxKit与Apache和mod_perl的集成,将这些更适合的工具委托给图像处理。
这是通过使用缩略图图像文件的特殊URL和自定义mod_perl处理程序My::Thumbnailer来完成的,以将全尺寸图像转换为缩略图。AxKit和mod_perl代码都不会用于提供图像,这将留给Apache处理。
缩略图将自动生成与主图像文件同名的文件,并在前面加上一个前置点(“.”)。在Unix世界中,这表示一个隐藏文件,我们不希望缩略图(或其他点文件)出现在我们的画廊页面上。
My::Thumbnailer使用Arnar M. Hrafnkelsson和Tony Cook开发的相对较新的Imager模块。这是一个竞争GD、Image::Magick和Graphics::Libplot等著名模块的顶级模块。Imager因其速度、质量和功能齐全的API而享有盛誉。
`.meta`文件
在我们深入实现之前,让我们看看这个设计的一个更微妙的地方。我们之前的示例都是直线管道,依次将源文档处理成HTML页面。然而,在这个应用程序中,我们将从源文档和我们将称之为元文件集的相关文件中引导数据。
这个微妙之处在截图中并不明显,但如果你仔细观察,可以看到第一张图像的标题(“婴儿照片”)包含比其他八张图像的标题更多的信息。这是因为第一张图像有一个包含要显示的标题和注释的元文件,而其他图像则没有(尽管它们可以)。
第一张图像(“婴儿照片”)来自名为a-look.jpeg的文件,该目录中有一个名为a-look.meta的元文件,看起来像(粗体显示最终发送到浏览器的数据)
该文件的一个重要特性是,其内容和在标题区域内的展示方式完全由核心图像库代码未指定。这使得我们的图像库具有高度的定制性:网站设计师可以确定需要与每张图像关联的元信息,以及如何展示这些信息。数据可以显示在缩略图标题中、在展开视图中,或用于非显示目的。
以下是每个标题区域包含的内容
- 标题。如果找到了一个图像的 .meta 文件并且它有一个非空的
<title>元素,则将其用作名称,否则将使用图像的文件名去除扩展名。 - 图像文件的最后修改时间(遗憾的是,以服务器本地时间为准)。
- 注释(可选):如果 .meta 文件中有一个
<comment>元素,包括 XHTML 标记,则将其显示。
为什么每张图像都有一个 .meta 文件而不是一个大文件?这希望允许管理员一起管理图像和元文件,并允许我们通过单个文件访问图像的元信息,这是在 AxKit 中自然要做的。通过为每张图像配备一对文件,您可以使用简单的文件系统操作来移动它们,或者使用文件系统链接使图像出现在多个目录中,可能具有相同的元文件,也可能具有不同的元文件。这样我们就无需开发很多复杂的功能来充分利用我们的图像库(尽管如果需要,我们可以这样做)。
管道
没有详细说明管道的 AxKit 实现文档是不完整的。以下是上面显示的图像证明页面管道(单击任何方框可跳转到有关该管道部分的讨论,单击该图表的任何小版本可跳转到此图)
|
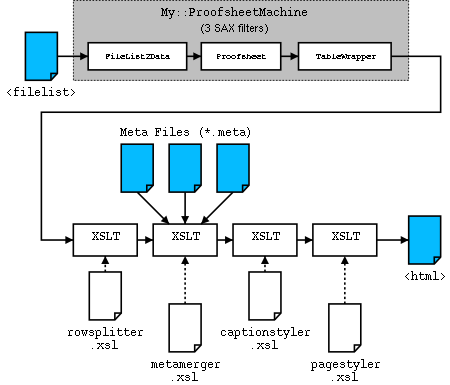
在这种情况下,与之前的管道不同,数据不是以纯粹线性的方式流动:AxKit 的目录列表(<filelist>)为管道提供数据,并经过三个 SAX 过滤器和四个 XSLT 过滤器的处理。有这么多过滤器是因为这个应用程序旨在通过调整特定的过滤器或向管道添加其他过滤器来进行定制。它还使用了 CPAN 上可用的几个 SAX 过滤器,以使我们的生活更加轻松。
在实际使用中,您可能需要添加更多过滤器,例如用于品牌、通过为不同的目录层次结构提供不同的背景或标题来区分图像组、添加广告横幅等。
以下是每个过滤器的作用的简要描述以及为什么每个都是一个独立的过滤器
- My::ProofSheetMachine 是一个短小的模块,它构建一个 SAX Machine Pipeline。在这个应用程序中,使用 SAX 过滤器来处理更适合 Perl 而不是 XSLT 或 XSP 的任务。
- My::FileList2Data 是另一个短小的模块,它使用 CPAN 上的 XML::Simple 模块将
<filelist>转换为 Perl 数据结构,然后传递下去。这是它自己的过滤器,因为我们希望在传递下去之前对 XML::Simple 和结果数据结构进行一些定制。 - My::ProofSheet 是生成图像库页面的核心。它从文件列表数据结构中构建图像列表,并添加有关缩略图图像和元文件的信息。
- XML::Filter::TableWrapper 是 CPAN 上的一个模块,用于将可能很长的图像列表包装成每行不超过五个图像的行。
- My::FileList2Data 是另一个短小的模块,它使用 CPAN 上的 XML::Simple 模块将
- rowsplitter.xsl 将每行图像拆分为两个表格行:一个用于图像,另一个用于标题。在XSLT中比在SAX中更容易做到这一点,因此这里我们从SAX处理转移到XSLT处理。
- metamerger.xsl 检查每个标题,看My::ProofSheet是否在其中放置了元文件的URL。如果是这样,它将打开元文件并将其插入到标题中。这是一个单独的过滤器,因为网站管理员可能希望在这里编写一个自定义过滤器,以集成来自某些其他来源的元信息,例如单个主文件或集中式数据库。
- captionstyler.xsl 检查每个标题并将其重新编写为XHTML。这是一个单独的过滤器,原因有两个:它允许在不干扰其他过滤器的情况下更改标题的外观和感觉;因为它是最关心元文件内容的过滤器,网站管理员可以更改元文件的架构,然后更改此过滤器以匹配。
- pagestyler.xsl 将标题元素之外的所有内容转换为HTML。它是单独的,以便可以按站点或按目录更改页面外观和感觉,而不会影响标题内容等。
关于此设计有几个要点需要注意。首先,将处理过程拆分为多个过滤器,使管理员能够修改网站的内容和样式。其次,由于AxKit建立在Apache配置引擎之上,因此可以根据URL、目录路径、查询字符串参数、浏览器类型等选择用于特定目录请求的过滤器。第三,值得注意的是使用SAX处理器处理在Perl中实现起来更容易(在某些情况下容易得多)的任务,而当使用XSLT时,则更有效(程序员和/或处理器)。
配置
以下是配置AxKit以执行所有这些操作的步骤
##
## Init the httpd to use our "private install" libraries
##
PerlRequire startup.pl
##
## AxKit Configuration
##
PerlModule AxKit
<Directory "/home/me/htdocs">
Options -All +Indexes +FollowSymLinks
# Tell mod_dir to translate / to /index.xml or /index.xsp
DirectoryIndex index.xml index.xsp
AddHandler axkit .xml .xsp
AxDebugLevel 10
AxTraceIntermediate /home/me/axtrace
AxGzipOutput Off
AxAddXSPTaglib AxKit::XSP::Util
AxAddXSPTaglib AxKit::XSP::Param
AxAddStyleMap text/xsl \
Apache::AxKit::Language::LibXSLT
AxAddStyleMap application/x-saxmachines \
Apache::AxKit::Language::SAXMachines
</Directory>
<Directory "/home/me/htdocs/04">
# Enable XML directory listings (see Generating File Lists)
AxHandleDirs On
#######################
# Begin pipeline config
AxAddRootProcessor application/x-saxmachines . \
{http://axkit.org/2002/filelist}filelist
PerlSetVar AxSAXMachineClass "My::ProofSheetMachine"
# The absolute stylesheet URLs are because
# I prefer to keep stylesheets out of the
# htdocs for security reasons.
AxAddRootProcessor text/xsl file:///home/me/04/rowsplitter.xsl \
{http://axkit.org/2002/filelist}filelist
AxAddRootProcessor text/xsl file:///home/me/04/metamerger.xsl \
{http://axkit.org/2002/filelist}filelist
AxAddRootProcessor text/xsl file:///home/me/04/captionstyler.xsl \
{http://axkit.org/2002/filelist}filelist
AxAddRootProcessor text/xsl file:///home/me/04/pagestyler.xsl \
{http://axkit.org/2002/filelist}filelist
# End pipeline config
#####################
# This is read by My::ProofSheetMachine
PerlSetVar MyColumns 5
# This is read by My::ProofSheet
PerlSetVar MyMaxX 100
# Send thumbnail image requests to our
# thumbnail generator
<FilesMatch "^\.">
SetHandler perl-script
PerlHandler My::Thumbnailer
PerlSetVar MyMaxX 100
PerlSetVar MyMaxY 100
</FilesMatch>
</Directory>
第一个 <Directory> 部分包含我们在 文章1 中引入的AxKit指令以及一个新的样式表映射,允许我们使用SAX机器在管道中。否则,所有与这个示例相关的配置指令都位于 <Directory "/home/me/htdocs/04"> 部分。
我们在本系列的 文章1 和 文章2 中看到了AxKit与Apache配置引擎协同工作的基本示例。我们将使用这个照片画廊应用程序在未来的文章中演示许多更强大的机制。
通过设置 AxHandleDirs On,我们告诉AxKit在04目录及其以下生成 <filelist> 文档(在生成文件列表部分描述)。
然后,我们配置04目录层次结构的管道。为此,我们利用AxKit将所有元素都放入 http://axkit.org/2002/filelist 命名空间的事实。AxAddRootProcessor 的第三个参数导致AxKit检查它从04目录树提供的所有文档,并检查根元素是否与命名空间和元素名称匹配。
这是按照James Clark在他在 XML命名空间简介 中使用的表示法来指定的。
如果文档匹配(所有AxKit生成的文件列表都将匹配),则将第一个两个参数指定的MIME类型和样式表添加到管道中。四个 AxAddRootProcessor 指令添加了我们在 “管道”部分 中描述的SAX机器和四个XSLT过滤器。
当将SAX机器加载到管道中时,您可以给它一个简单的SAX过滤器列表(在CPAN上有许多可用的过滤器),它将构建一个过滤器管道。这是通过一个(未显示)PerlSetVar AxSAXMachineFilters "..."指令完成的。这个指令的限制是您不能向过滤器传递任何初始化值,而我们希望这样做。
因此,我们改用PerlSetVar AxSAXMachineClass "My::ProofSheetMachine"来告诉Apache::AxKit::Language::SAXMachines模块加载类My::ProofSheetMachine,并让该类构建SAX机器。
配置的最后一部分使用一个<Files>部分将所有缩略图图像请求转发到My::Thumbnailer中的mod_perl处理器。
遍历管道
现在我们已经放置了过滤器,让我们遍历管道并查看每个过滤器和它发出的内容。
生成文件列表

首先,看看这个作为链的输入的<filelist>文档。这是AxKit在以与Apache创建HTML目录列表相同的方式处理目录请求时创建的。只有在AxHandleDirs On指令时,AxKit才会生成这些页面。这导致AxKit扫描目录以查找上述截图并发出类似XML的内容(添加了空白,省略了重复的内容)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE filelist PUBLIC
"-//AXKIT/FileList XML V1.0//EN"
"file:///dev/null"
>
<filelist xmlns="http://axkit.org/2002/filelist">
<directory
atime="1032276941"
mtime="1032276939"
ctime="1032276939"
readable="1"
writable="1"
executable="1"
size="4096" >.</directory>
<directory ...>..</directory>
<directory ...>Mary</directory>
<directory ...>Jim</directory>
<file mtime="1031160766" ...>a-look.jpeg</file>
<file mtime="1031160787" ...>a-lotery.jpeg</file>
<file mtime="1031160771" ...>a-lucky.jpeg</file>
<file mtime="1032197214" ...>a-look.meta</file>
<file mtime="1035239142" ...>foo.html</file>
...
</filelist>
加粗的部分是我们想要显示的数据:一些文件名和它们的修改时间。一些需要注意的事项
- 所有元素——最重要的是我们将在下面看到根元素——都在一个特殊命名空间中,即
http://axkit.org/2002/filelist,使用xmlns=属性(有关详细信息,请参阅James Clark的介绍)。 - 条目是无序的。我们可能在将来允许用户按不同的属性进行排序,但这意味着我们至少需要以某种方式对结果进行排序。
- 它们包含来自
stat()系统调用的完整输出作为属性,因此我们可以使用mtime属性来推导出修改时间。 - 其中包含一些文件(
a-look.meta和foo.html)显然不应显示为图像。 a-look.jpeg的文件名没有加粗:我们将使用来自a-look.meta文件的<title>元素。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE filelist PUBLIC
"-//AXKIT/FileList XML V1.0//EN"
"file:///dev/null"
>
<filelist xmlns="http://axkit.org/2002/filelist">
<directory
atime="1032276941"
mtime="1032276939"
ctime="1032276939"
readable="1"
writable="1"
executable="1"
size="4096" >.</directory>
<directory ...>..</directory>
<directory ...>Mary</directory>
<directory ...>Jim</directory>
<file mtime="1031160766" ...>a-look.jpeg</file>
<file mtime="1031160787" ...>a-lotery.jpeg</file>
<file mtime="1031160771" ...>a-lucky.jpeg</file>
<file mtime="1032197214" ...>a-look.meta</file>
<file mtime="1035239142" ...>foo.html</file>
...
</filelist>
My::ProofSheetMachine
处理管道由My::ProofSheetMachine模块构建的三个SAX过滤器启动
package My::ProofSheetMachine;
use strict;
use XML::SAX::Machines qw( Pipeline );
use My::ProofSheet;
use XML::Filter::TableWrapper;
sub new {
my $proto = shift;
return bless {}, ref $proto || $proto;
}
sub get_machine {
my $self = shift;
my ( $r ) = @_;
my $m = Pipeline(
My::Filelist2Data
=> My::ProofSheet->new( Request => $r ),
=> XML::Filter::TableWrapper->new(
ListTags => "{}images",
Columns => $r->dir_config( "MyColumns" ) || 3,
),
);
return $m;
}
1;
此模块提供了一个最小的构造函数new(),以便它可以实例化(这是Apache::AxKit::Language::SAXMachines的要求,对我们来说不需要)。AxKit将在每次请求用于获取SAX机器时调用一次get_machine()方法。SAX机器不会在请求之间重用。
$r是Apache请求对象的一个引用(实际上,是对AxKit子类的引用)。这个引用被传递到My::ProofSheet,该引用用于与一些httpd.conf设置进行交互查询,以控制AxKit的缓存,并通过Apache探查文件系统。
在这个模块中查询$r以查看是否为该请求设置了MyColumns设置,如果没有设置,则使用默认值。ListTags设置告诉XML::Filter::TableWrapper将第一个两个过滤器生成的图像列表分成图像行(换句话说,准备将其作为HTML表格)。
将此类参数传递给SAX过滤器的需要是我们使用此类SAX机器工厂类的唯一原因。此类由PerlSetVar AxSAXMachineClass指定;如果我们不需要以这种方式初始化过滤器,那么我们可以在PerlSetVar AxSAXMachineFilters指令中列出它们。有关SAX机器如何与AxKit集成的更多详细信息,请参阅手册页
当前,AxKit管道中一次只能允许一个SAX机器(尽管不同的管道可以包含不同的机器)。这更多的是配置系统的限制,如果需要的话,可能会改变。然而,如果我们需要将SAX处理器添加到机器的末尾,那么可以使用PerlSetVar AxSAXMachineFilters在主机器(以及在XSLT处理器之前)之后插入特定于站点的过滤器。
My::Filelist2Data
将<filelist>转换为校样需要一些详细的数据处理。在Perl中这相当简单,因此我们管道中的第一步是将XML文件列表转换为数据。《a href="https://metacpan.org/pod/XML::Simple">XML::Simple
package My::Filelist2Data;
use XML::Simple;
@ISA = qw( XML::Simple );
use strict;
sub new {
my $proto = shift;
my %opts = @_;
# The Handler value is passed in by the Pipeline()
# call in My::ProofSheetMachine.
my $h = delete $opts{Handler};
# Even if there's only one file element present,
# make XML::Simple put it in an ARRAY so that
# the downstream filter can depend on finding an
# array of elements and not a single element.
# This is an XML::Simple option that is almost
# always set in practice.
$opts{forcearray} = [qw( file )];
# Each <file> and <directory> element contains
# the file name as simple text content. This
# option tells XML::Simple to store it in the
# data member "filename".
$opts{contentkey} = "filename";
# This subroutine gets called when XML::Simple
# has converted the entire document with the
# $data from the document.
$opts{DataHandler} = sub {
shift;
my ( $data ) = @_;
# If no files are found, place an array
# reference in the right spot. This is to
# to simplify downstream filter code.
$data->{file} ||= [];
# Pass the data structure to the next filter.
$h->generate( $data );
} if $h;
# Call XML::Simple's constructor.
return $proto->SUPER::new( %opts );;
}
1;
使用非SAX事件在SAX机器之间发送此类数据结构被称为“作弊”。但这是Perl,允许你负责任和审慎地作弊是Perl的伟大优势之一。这在可预见的未来是可行的。如果你打算为通用过滤器做类似的事情,那么你最好也提供set_handler和get_handler方法,以便你的过滤器在实例化后可以被重新定位(XML::SAX::Machines在需要时可以这样做),但在这个单一用途的示例中我们不需要让它变得杂乱。
<filelist>文档被转换为Perl数据结构,其中每个元素都是一个HASH或数组中的数据成员,例如(省略并重新排列以与源XML相关)
{
xmlns => 'http://axkit.org/2002/filelist',
directory => [
{
atime => '1032276941'
mtime => '1032276939',
ctime => '1032276939',
readable => '1',
writable => '1',
executable => '1',
size => '4096',
content => '.',
},
{
...
content => '..',
},
{
...
content => 'Mary',
},
{
...
content => 'Jim',
}
]
file => [
{
mtime => '1031160766',
...
content => 'a-look.jpeg',
},
{
mtime => '1031160787',
...
content => 'a-lotery.jpeg',
},
{
mtime => '1031160771',
...
content => 'a-lucky.jpeg',
},
{
mtime => '035239142',
...
content => 'foo.html',
},
...
],
}
My::ProofSheet
一旦数据在Perl数据结构中,就可以很容易地调整它(例如将mtime字段转换为可读的格式)并扩展它(例如添加有关缩略图图像和.meta文件的信息)。这就是My::ProofSheet所做的工作。
package My::ProofSheet;
use XML::SAX::Base;
@ISA = qw( XML::SAX::Base );
# We need to access the Apache request object to
# get the URI of the directory we're presenting,
# its physical location on disk, and to probe
# the files in it to see if they are images.
use Apache;
# My::Thumbnailer is an Apache/mod_perl module that
# creates thumbnail images on the fly. See below.
use My::Thumbnailer qw( image_size thumb_limits );
# XML::Generator::PerlData lets us take a Perl data
# structure and emit it to the next filter serialized
# as XML.
use XML::Generator::PerlData;
use strict;
sub generate {
my $self = shift;
my ( $data ) = @_;
# Get the AxKit request object so we can
# ask it for the URI and use it to test
# whether files are images or not.
my $r = $self->{Request};
my $dirname = $r->uri; # "/04/Baby_Pictures/Other/"
my $dirpath = $r->filename; # "/home/me/htdocs/...Other/"
my @images = map $self->file2image( $_, $dirpath ),
sort {
$a->{filename} cmp $b->{filename}
} @{$data->{file}};
# Use a handy SAX module to generate XML from our Perl
# data structures. The XML will look basically like:
# Write XML that looks like
#
# <proofsheet>
# <images>
# <image>...</image>
# <image>...</image>
# ...
# </images>
# <title>/04/BabyePictures/Others</title>
# </proofsheet>
#
XML::Generator::PerlData->new(
rootname => "proofsheet",
Handler => $self,
)->parse( {
title => $dirname,
images => { image => \@images },
} );
}
sub file2image {
my $self = shift;
my ( $file, $dirpath ) = @_;
# Remove the filename from the fields so it won't
# show up in the <image> structure.
my $fn = $file->{filename};
# Ignore hidden files (first char is a ".").
# Thumbnail images are cached as hidden files.
return () if 0 == index $fn, ".";
# Ignore files Apache knows aren't images
my $type = $self->{Request}->lookup_file( $fn )->content_type;
return () unless
defined $type
&& substr( $type, 0, 6 ) eq "image/";
# Strip the extension(s) off.
( my $name = $fn ) =~ s/\..*//;
# A meta filename is the image filename with a ".meta"
# extension instead of whatever extension it has.
my $meta_fn = "$name.meta";
my $meta_path = "$dirpath/$meta_fn";
# The thumbnail file is stored as a hidden file
# named after the image file, but with a leading
# '.' to hide it.
my $thumb_fn = ".$fn";
my $thumb_path = "$dirpath/$thumb_fn";
my $last_modified = localtime $file->{mtime};
my $image = {
%$file, # Copy all fields
type => $type, # and add a few
name => $name,
thumb_uri => $thumb_fn,
path => "$dirpath/$fn",
last_modified => $last_modified,
};
if ( -e $meta_path ) {
# Only add a URI to the meta info, metamerger.xsl will
# slurp it up if and only if <meta_uri> is present.
$image->{meta_filename} = $meta_fn;
$image->{meta_uri} = "file://$meta_path";
}
# If the thumbnail exists, grab its width and height
# so later stages can populate the <img> tag with them.
# The eval {} is in case the image doesn't exist or
# the library can't cope with the image format.
# Disable caching AxKit's output if a failure occurs.
eval {
( $image->{thumb_width}, $image->{thumb_height} )
= image_size $thumb_path;
} or $self->{Request}->no_cache( 1 );
return $image;
}
1;
当My::Filelist2Data调用generate()时,generate()会按文件名对文件列表进行排序和扫描,将每个文件转换为图像,并将页面标题以及生成的图像列表发送到下一个过滤器(《a href="/pub/2002/09/24/axkit.html?page=3#XML::Filter::TableWrapper">XML::Filter::TableWrapper)。Kip Hampton的《a href="https://metacpan.org/pod/XML::Generator::PerlData">XML::Generator::PerlData》是一个Perl数据到XML序列化模块。它不是用于生成通用XML;它专注于构建Perl数据结构的XML表示。在这种情况下,这是理想的,因为我们将通过XSLT模板生成输出文档,我们不关心每个<image>元素中元素的精确顺序,每个<image>元素只是一个键/值对的哈希。然而,我们可以通过将有序的元素列表传递给XML::Generator::PerlData作为数组来控制<image>元素的顺序。
按文件名排序可能不是所有应用的首选做法,因为用户可能更喜欢按图像的标题排序,但也许他们不会,这也允许网站管理员通过适当命名文件来控制排序顺序。我们总是可以稍后添加排序功能。
此代码的另一个特性是它不能保证有thumb_width和thumb_height值可用。如果你只是将源图像放入目录中,那么服务器生成此页面的第一次,将没有缩略图可用。在这种情况下,调用no_cache(1)会阻止AxKit缓存输出页面,这样低效的HTML就不会被卡在缓存中。这将给服务器另一个机会用适当的标签生成它,当然希望在下一次请求此页面时,所需的缩略图将可用。
这种方法可以快速将HTML传递到浏览器,因此用户浏览器窗口将迅速清除并开始填充页面顶部,用户将看到一些活动,不太可能感到不耐烦。缩略图将在浏览器看到所有<img>标签时生成。另一种方法是内联生成缩略图,这将在大量列表的第一个HTML到达浏览器之前造成显著延迟,或者预先生成缩略图。
关于这种方法的一个注意事项是,许多浏览器会一次请求多张图片,这将导致多个服务器进程同时为多张不同的图片生成缩略图。这应该在低负载服务器上导致更低的延迟,因为进程可以交错CPU时间和磁盘I/O等待,并且如果存在的话,可以利用多个处理器。当然,在高度负载的服务器上,这可能是一件坏事;预先生成缩略图那里是个好主意。
此过滤器的输出如下
<?xml version="1.0"?>
<proofsheet>
<images>
<image>
<path>
/home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.jpeg
</path>
<writable>1</writable>
<filename>a-look.jpeg</filename>
<thumb_uri>.a-look.jpeg</thumb_uri>
<meta_filename>a-look.meta</meta_filename>
<name>a-look</name>
<last_modified>Wed Sep 4 13:32:46 2002</last_modified>
<ctime>1032552249</ctime>
<meta_uri>
file:///home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.meta
</meta_uri>
<mtime>1031160766</mtime>
<size>8522</size>
<readable>1</readable>
<type>image/jpeg</type>
<atime>1032553327</atime>
</image>
<image>
<path>
/home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-lotery.jpeg
</path>
<writable>1</writable>
<filename>a-lotery.jpeg</filename>
<thumb_uri>.a-lotery.jpeg</thumb_uri>
<name>a-lotery</name>
<last_modified>Wed Sep 4 13:33:07 2002</last_modified>
<ctime>1032552249</ctime>
<mtime>1031160787</mtime>
<size>10113</size>
<readable>1</readable>
<type>image/jpeg</type>
<atime>1032553327</atime>
</image>
</images>
...
<title>/04/Baby_Pictures/Others</title>
</proofsheet>
原始<file>元素的所有数据都包含在每个<image>元素中,以及新字段。请注意,第一个<image>包含<meta_uri>(指向a-look.meta),而第二个不包含,因为没有a-lotery.meta。正如预期的那样,两者都有<thumb_uri>标签。粗体字的部分是我们演示想要的部分;你的可能需要更多或不同的部分。
虽然这个结构中有很多额外信息,但这实际上只是一个系统调用(stat())的输出以及My::ProofSheet操作的一些可能有用的副产品,因此这是一些前端可能需要的非常便宜的信息。这也比只发出示例前端可能需要的信息更容易,并使任何未来的上游过滤器或AxKit目录扫描扩展都能发挥作用。
没有<thumb_width>或<thumb_height>标签,因为我从axtrace目录复制了这个文件(见我们的httpd.conf文件中的AxTraceIntermediate指令)后查看了一个新添加的目录。以下是浏览器请求所有缩略图后第一个<image>元素的外观
<?xml version="1.0"?>
<proofsheet>
<images>
<image>
<thumb_width>72</thumb_width>
<path>
/home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.jpeg
</path>
<writable>1</writable>
<filename>a-look.jpeg</filename>
<thumb_height>100</thumb_height>
<thumb_uri>.a-look.jpeg</thumb_uri>
<meta_filename>a-look.meta</meta_filename>
<name>a-look</name>
<last_modified>Wed Sep 4 13:32:46 2002</last_modified>
<ctime>1032552249</ctime>
<meta_uri>
file:///home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.meta
</meta_uri>
<mtime>1031160766</mtime>
<size>8522</size>
<readable>1</readable>
<type>image/jpeg</type>
<atime>1032784360</atime>
</image>
...
</images>
<title>/04/Baby_Pictures/Others</title>
</proofsheet>
XML::Filter::TableWrapper
XML::Filter::TableWrapper是一个CPAN模块,用于将<images>列表分割成多个部分,在每个(可配置的)<image>元素周围插入<tr>...</tr>标签。此配置是通过我们之前展示的My::ProofSheetMachine模块完成的
XML::Filter::TableWrapper->new(
ListTags => "{}images",
Columns => $r->dir_config( "MyColumns" ) || 3,
),
对于我们的9张图片列表,输出如下
<?xml version="1.0"?>
<proofsheet>
<images>
<tr>
<image>
...
</image>
... 4 more image elements...
</tr>
<tr>
<image>
...
</image>
... 3 more image elements...
</tr>
</images>
<title>/04/Baby_Pictures/Others</title>
</proofsheet>
现在所有的表示样式表(pagestuler.xsl)都可以根据<tr>标签构建一个HTML <table>,或者如果它想以列表格式显示,则忽略它们(并且不通过它们)。
虽然我相信这在XSLT中是可能的,但我不知道如何轻松做到这一点。
rowsplitter.xsl
对这个应用程序的一个早期版本的实验表明,当缩略图的高度不同时,在同一个表格单元格中显示标题会导致标题以不同的高度显示。这使得扫描标题变得困难,并为页面添加了大量视觉杂乱。
一个解决方案是添加一个XSLT过滤器,将每个图像数据表格行分割成两行,一行用于缩略图,另一行用于标题。
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
<xsl:template match="image" mode="caption">
<caption>
<xsl:copy-of select="@*|*|node()" />
</caption>
</xsl:template>
<xsl:template match="images/tr">
<xsl:copy-of select="." />
<tr><xsl:apply-templates select="image" mode="caption" /></tr>
</xsl:template>
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
这个样式表中的第二个模板匹配到<images>元素中的每一行(<tr>元素),并将它原封不动地复制,然后在它的后面立即发出一个第二个<tr>元素,其中包含一个<caption>元素的列表,这些元素复制了原始行中每个<image>标签的内容。由于mode="caption"属性,第一个模板仅在创建第二行时应用于<image>标签。
第三个模板是标准的XSLT样板代码,它传递所有未被前两个模板匹配的XML。否则,这些XML会被默认的怪异XSLT规则搞得一团糟。
现在,我知道在AxKit环境中用Perl做这件事的几种方法,但没有一种像使用XSLT那样简单。(YMMV)。
那个阶段的输出看起来像
<?xml version="1.0"?>
<proofsheet>
<images>
<tr><image>... </image> ...total of 5... </tr>
<tr><caption>...</caption> ...total of 5... </tr>
<tr><image>... </image> ...total of 4... </tr>
<tr><caption>...</caption> ...total of 4... </tr>
</images>
<title>/04/Baby_Pictures/Others</title>
</proofsheet>
每个<image>标签和每个<caption>标签的内容都相同。这样进行转换更简单,并允许前端样式表有灵活性,例如,将图像文件名或修改时间放在与缩略图相同的单元格中。
metamerger.xsl
与行分割器一样,在XSLT中表达合并是合并外部XML文档的一种便捷方式,原因有几个。首先,出于效率的考虑:我们已经在过滤器前后使用了XSLT,AxKit优化了XSLT到XSLT的手动传递以避免重新解析。另一个原因是AxKit的XSLT引擎的底层实现是快速的libxslt的C。第三个原因是我们在这一阶段根本不改变传入的文件,所以XSLT不会失控(我不认为XSLT是一个非常易读的编程语言;它的XML语法使得源代码非常晦涩)。
另一种方法是回过头去修改My::ProofSheet以从XML::Filter::Merger继承,并使用SAX解析器插入它。这可能会慢一些,因为我怀疑SAX解析通常比XSLT的内部解析慢。这将剥夺应用程序通过将合并作为单独的步骤而产生的可配置性。通过将此功能纳入metamerger.xsl样式表,我们为网站设计师提供了从其他来源提取数据,甚至在没有元数据的情况下飞行的能力。
这就是metamerger.xsl的样子
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
<xsl:template match="caption">
<caption>
<xsl:copy-of select="*|@*|node()" />
<xsl:copy-of select="document( meta_uri )" />
</caption>
</xsl:template>
<xsl:template match="*|@*">
<xsl:copy>
<xsl:apply-templates select="*|@*|node()" />
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
第一个模板完成了匹配每个<caption>元素并复制其内容的全部工作,然后如果存在,解析并插入由<meta_uri>元素指示的文档。如果不存在<meta_uri>,则document()函数变为空操作。第二个模板是我们在rowsplitter.xsl中看到的相同样板代码,用于复制我们未明确匹配的任何内容。
这就是现在a-look.jpeg的<caption>标签看起来像的(其他所有<caption>标签都保持不变,因为没有这个目录中的其他.meta文件)
<caption>
<thumb_width>72</thumb_width>
<path>/home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.jpeg</path>
<writable>1</writable>
<filename>a-look.jpeg</filename>
<thumb_height>100</thumb_height>
<thumb_uri>.a-look.jpeg</thumb_uri>
<meta_filename>a-look.meta</meta_filename>
<name>a-look</name>
<last_modified>Wed Sep 4 13:32:46 2002</last_modified>
<ctime>1032552249</ctime>
<meta_uri>file:///home/barries/src/mball/AxKit/www/htdocs/04/Baby_Pictures/Others/a-look.meta</meta_uri>
<mtime>1031160766</mtime>
<size>8522</size>
<readable>1</readable>
<type>image/jpeg</type>
<atime>1032784360</atime>
<meta>
<title>A baby picture</title>
<comment><b>ME!</b>. Well, not really. Actually, it's some random image from the 'net.
</comment>
</meta>
</caption>
如前所述,这个样式表不在乎你放在元文件中的内容,它只是从根元素开始插入该文件中的任何内容。因此,你可以自由地将应用程序需要的任何元信息放在元文件中,并调整呈现过滤器以按你的意愿进行样式化。
由于我们知道我们的呈现将不需要其中任何内容,因此不会将.meta信息插入到<image>标签中。
captionstyler.xsl
我们管道的最后两个阶段将迄今为止收集的数据转换为HTML。这是在两个阶段中完成的,以便将一般布局和呈现与标题的呈现分开,因为这些呈现部分可能需要在不同图像集合之间独立变化。
这个示例的标题样式表是
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
<xsl:template match="caption">
<caption width="100" align="left" valign="top">
<a href="{filename}">
<xsl:choose>
<xsl:when test="meta/title and string-length( meta/title )">
<xsl:copy-of select="meta/title/node()" />
</xsl:when>
<xsl:otherwise>
<xsl:value-of select="name" />
</xsl:otherwise>
</xsl:choose>
</a><br />
<font size="-1" color="#808080">
<xsl:copy-of select="last_modified/node()" />
<br />
</font>
<xsl:copy-of select="meta/comment/node()" />
</caption>
</xsl:template>
<xsl:template match="*|@*|node()">
<xsl:copy>
<xsl:apply-templates />
</xsl:copy>
</xsl:template>
</xsl:stylesheet>
第一个模板将所有 <caption> 元素替换为具有默认宽度和对齐方式的新 <caption> 单元格,然后填充这些单元格,其中包含图像的名称,该名称也是指向底层图像文件的链接,以及由 My::ProofSheet 格式化的 <last_modified 时间字符串和元文件中可能存在的任何 <comment>。
<xsl:choose> 元素用于选择显示图像的标题。第一个 <xsl:when> 查看元文件中是否存在 <title> 元素,如果存在则使用它。默认情况下,<xsl:otherwise> 将名称设置为 My::ProofSheet 设置的 <name>。
此阶段输出的标题看起来像
<caption width="100" align="left" valign="top">
<a href="a-look.jpeg">A baby picture</a>
<br/>
<font size="-1" color="#808080">Wed Sep
4 13:32:46 2002<br/>
</font>
<b>ME!</b>. Well, not really. Actually, it's
some random image from the 'net.
</caption>
<caption width="100" align="left" valign="top">
<a href="a-lotery.jpeg">a-lotery</a>
<br/>
<font size="-1" color="#808080">Wed Sep
4 13:33:07 2002<br/></font>
</caption>
前者是找到 .meta 文件时输出的内容,后者是没有找到时输出的内容。
pagestyler.xsl
现在,最后阶段。如果你已经走到这一步,恭喜你;这是一个真正的应用的开端,而不仅仅是玩具,所以花了一些时间才到这里。
处理管道的最后阶段生成一个 HTML 页面,除了 <caption> 标签的属性和内容,它原样传递。
<xsl:stylesheet
version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
>
<xsl:template match="/*">
<html>
<head>
<title>Images in <xsl:value-of select="title" /></title>
</head>
<body bgcolor="#ffffff">
<xsl:apply-templates select="images" />
</body>
</html>
</xsl:template>
<xsl:template match="images">
<table>
<xsl:apply-templates />
</table>
</xsl:template>
<xsl:template match="tr">
<xsl:copy>
<xsl:apply-templates select="*" />
</xsl:copy>
</xsl:template>
<xsl:template match="image">
<td align="left" valign="top">
<a href="{filename}">
<img border="0" src="{thumb_uri}">
<xsl:if test="thumb_width">
<xsl:attribute name="width">
<xsl:value-of select="thumb_width" />
</xsl:attribute>
</xsl:if>
<xsl:if test="thumb_height">
<xsl:attribute name="height">
<xsl:value-of select="thumb_height" />
</xsl:attribute>
</xsl:if>
</img>
</a>
</td>
</xsl:template>
<xsl:template match="@*|node()" mode="caption">
<xsl:copy>
<xsl:apply-templates select="@*|node()" mode="caption" />
</xsl:copy>
</xsl:template>
<xsl:template match="caption">
<td>
<xsl:apply-templates select="@*|node()" mode="caption" />
</td>
</xsl:template>
</xsl:stylesheet>
第一个模板生成 HTML 页面的骨架,第二个模板从源文档中获取 <images> 列表,输出一个 <table>,第三个模板复制 <tr> 标签,第四个模板将所有 <image> 标签替换为包含缩略图图像作为底层图像链接的 <td> 标签(类似于 captionstyler.xsl 对图片名称的处理)。这里的唯一细微之处在于,如果存在,将使用可选的 <thumb_width> 和 <thumb_height> 元素来告知浏览器缩略图的大小,以加快布局过程(如前所述,不包含此信息的页面不会被缓存,以便在生成缩略图时,将生成带有该信息的新的 HTML)。
第四个模板将 <caption> 元素转换为 <td> 元素,并将所有内容复制过来,因为 captionstyler.xsl 已经为他们做了展示。
调整此样式表或替换它控制整个页面布局,除了缩略图大小(这由 httpd.conf 中的可选 MyMaxX 和 MyMaxY PerlSetVar 设置决定)。在链中的此点,不同的样式表可以选择忽略 <tr> 标签,并输出列表样式输出。稍后的样式表可以添加品牌或广告等。
My::ThumbNailer
这是生成缩略图的 Apache 模块。关键要记住的是,与本文中展示的所有其他代码和 XML 不同,这个模块是为每个缩略图图像而不是每个目录调用的。当浏览器请求目录列表时,它从上面的管道中获取包含许多缩略图图像 URI 的 HTML。然后它通常依次请求这些 URI 中的每一个。在 httpd.conf 文件中,所有对点文件的请求都指向此模块。
package My::Thumbnailer;
# Allow other modules like My::ProofSheet to use some
# of our utility routines.
use Exporter;
@ISA = qw( Exporter );
@EXPORT_OK = qw( image_size thumb_limits );
use strict;
use Apache::Constants qw( DECLINED );
use Apache::Request;
use File::Copy;
use Imager;
sub image_size {
my $img = shift;
if ( ! ref $img ) {
my $fn = $img;
$img = Imager->new;
$img->open( file => $fn )
or die $img->errstr(), ": $fn";
}
( $img->getwidth, $img->getheight );
}
sub thumb_limits {
my $r = shift;
# See if the site admin has placed MyMaxX and/or
# MyMaxY in the httpd.conf.
my ( $max_w, $max_h ) = map
$r->dir_config( $_ ),
qw( MyMaxX MyMaxY );
return ( $max_w, $max_h )
if $max_w || $max_h;
# Default to scaling down to fit in a 100 x 100
# pixel area (aspect ration will be maintained).
return ( 100, 100 );
}
# Apache/mod_perl is configured to call
# this handler for every dotfile
# requested. All thumbnail images are dotfiles,
# some dotfiles may not be thumbnails.
sub handler {
my $r = Apache::Request->new( shift );
# We only want to handle images.
# Let Apache handle non-images.
goto EXIT
unless substr( $r->content_type, 0, 6 ) eq "image/";
# The actual image filename is the thumbnail
# filename without the leading ".". There's
( my $orig_fn = $r->filename ) =~ s{/\.([^/]+)\z}{/$1}
or die "Can't parse ", $r->filename;
# Let Apache serve the thumbnail if it already
# exists and is newer than the original file.
{
my $thumb_age = -M $r->finfo;
my $orig_age = -M $orig_fn;
goto EXIT
if $thumb_age && $thumb_age <= $orig_age;
}
# Read in the original file
my $orig = Imager->new;
unless ( $orig->open( file => $orig_fn ) ) {
# Imager can't hack the format, fall back
# to the original image. This can happen
# if you forget to install libgif
# (as I have done).
goto FALLBACK
if $orig->errstr =~ /format not supported/;
# Other errors are probably more serious.
die $orig->errstr, ": $orig_fn\n";
}
my ( $w, $h ) = image_size( $orig );
die "!\$w for ", $r->filename, "\n" unless $w;
die "!\$h for ", $r->filename, "\n" unless $h;
my ( $max_w, $max_h ) = thumb_limits( $r );
# Scale down only, If the image is smaller than
# the thumbnail limits, let Apache serve it as-is.
# thumb_limits() guarantees that either $max_w
# or $max_h will be true.
goto FALLBACK
if ( ! $max_w || $w < $max_w )
&& ( ! $max_h || $h < $max_h );
# Scale down to the maximum dimension to the
# requested size. This can mess up for images
# that are meant to be scaled on each axis
# independantly, like graphic bars for HTML
# page seperators, but that's a very small
# demographic.
my $thumb = $orig->scale(
$w > $h
? ( xpixels => $max_w )
: ( ypixels => $max_h )
);
$thumb->write( file => $r->filename,)
or die $thumb->errstr, ": ", $r->filename;
goto BONK;
FALLBACK:
# If we can't or don't want to build the thumbnail,
# just copy the original and let Apache figure it out.
warn "Falling back to ", $orig_fn, "\n";
copy( $orig_fn, $r->filename );
BONK:
# Bump apache on the head just hard enough to make it
# forget the thumbnail file's old stat() and
# mime type since we've most likely changed all
# that now. This is important for the headers
# that control downstream caching, for instance,
# or in case Imager changed mime types on us
# (unlikely, but hey...)
$r->filename( $r->filename );
EXIT:
# We never serve the image data, Apache is perfectly
# good at doing this without our help. Returning
# DECLINED causes Apache to use the next handler in
# its list of handlers. Normally this is the default
# Apache file handler.
return DECLINED;
}
1;
应该有足够的内联注释来解释所有这些。唯一要说的是,为了避免出现 go-to 恐慌,我认为使用 goto 使得此例程比其他替代方案更清晰;早期版本没有使用它,可读性和可维护性较低。这是因为三个正常退出路线恰好从底部堆叠得很好,因此从一个标记块到下一个的跌落发生得很好。
这里最明显的错误是没有文件锁定。我们将在下次添加它。
总结
本文中代码的最终结果是构建我们文章开头显示的页面的图像校样部分。下一篇文章将完成该页面,然后在未来的文章中我们将构建图像展示页面和元数据编辑器。
帮助和感谢
如遇问题,请参阅我们列在第一篇文章中的部分有益资源。
标签
反馈
这篇文章有什么问题吗?请通过在GitHub上创建一个issue或pull request来帮助我们。

{kind=link}