




用Perl构建3D引擎,第4部分
本文是该系列的第4篇,旨在在Perl中构建一个完整的3D引擎。第一篇文章从基本的程序结构开始,逐渐发展到在OpenGL窗口中显示一个简单的深度缓冲场景。第二篇文章随后讨论了时间、视图动画、SDL事件、键盘处理以及大量重构。第三篇文章继续展示了截图、视图点的移动、简单的OpenGL光照和细分盒子面。
在上篇文章的结尾,引擎相当慢。本文将展示如何定位性能问题以及如何解决这个问题。然后,它将演示如何以不同的方式应用相同的新OpenGL技术,以创建屏幕上的帧率计数器。像往常一样,您可以通过下载示例代码来跟踪代码。
SDL_perl 发展
首先,有一个好消息——Win32用户不再被排除在外。多亏了Wayne Keenan,SDL_perl 1.x现在在Win32上完全支持OpenGL,并提供了预构建的二进制文件。更多细节在我的网站上的新SDL_perl 1.x页面上;浏览svn.openfoundry.org/sdlperl1的Subversion仓库。
如果您想帮助改进SDL_perl 1.x,请访问SDL_perl 1.x页面,检查代码并给我发送评论或补丁,或者在irc.freenode.net的#sdlperl上ping我。
评估引擎
如我在引言中提到的,当我上一次离开时,引擎几乎无法移动。现在是时候弄清楚原因并找出如何解决这个问题了。完成第一项工作的正确工具是性能分析器,它监视运行中的程序并跟踪其每个部分的性能。Perl的本地性能分析器是dprofpp,它跟踪程序中每个子例程花费的时间和调用次数。检查这些数字将显示引擎是否大部分时间都花在一个例程上,然后该例程将成为优化的焦点。
最好这些数字在每次运行之间相对可重复,使得在更改前后比较配置文件变得容易。对于渲染引擎,最简单的解决方案是基准模式。在基准模式下,引擎会运行一定时间或帧数,显示预定义的场景或序列。我选择通过在init_conf中的新设置启用基准模式。
benchmark => 1,
只要用户不按任何键,引擎就显示一个恒定的场景;剩下的要求是在设定的时间内退出。
在先前的文章中,我只是在渲染循环中硬编码了一个超时检查,但这次我选择了更通用的方法,使用触发事件。到目前为止,引擎的事件始终来自SDL,对外部输入的反应,如按键和窗口关闭事件。相比之下,引擎本身在模拟世界状态改变时产生触发事件,例如玩家试图打开门或攻击敌人。
为了收集这些事件,我在do_events的开始处添加了两行新代码;现在的开头是
sub do_events
{
my $self = shift;
my $queue = $self->process_events;
my $triggered = $self->triggered_events;
push @$queue, @$triggered;
在调用 process_events 处理 SDL 事件并将结果命令填充到 $queue 后,do_events 会调用 triggered_events 从任何待处理的内部生成事件中收集命令,并将它们添加到 $queue。目前 triggered_events 可以相当简单。
sub triggered_events
{
my $self = shift;
my @queue;
push @queue, 'quit' if $self->{conf}{benchmark} and
$self->{world}{time} >= 5;
return \@queue;
}
这基本上是将旧硬编码的超时代码直接翻译为命令队列概念。通常,triggered_events 简单地返回一个空数组引用,表示没有触发事件,因此没有生成命令。在基准模式下,当世界时间达到 5 秒时,队列中将添加退出命令。在 do_events 中的正常命令处理将处理其余部分。
dprofpp 是您的(模糊的)朋友
启用基准模式后,引擎在 dprofpp 下运行。第一步是收集配置文件数据
dprofpp -Q -p step065
-p step065 告诉 dprofpp 对名为 step065 的程序进行 *p*rofile,而 -Q 告诉它收集数据后 *q*uit。 dprofpp 运行 step065,收集配置文件数据,并将其存储在当前目录中名为 tmon.out 的特殊格式的文本文件中。
要将配置文件数据转换为人类可读的输出,我使用了不带任何参数的 dprofpp。它处理收集到的数据一段时间,最后生成了这个
$ dprofpp
Exporter::Heavy::heavy_export_to_level has 4 unstacked calls in outer
Exporter::export_to_level has -4 unstacked calls in outer
Exporter::export has -12 unstacked calls in outer
Exporter::Heavy::heavy_export has 12 unstacked calls in outer
Total Elapsed Time = 4.838377 Seconds
User+System Time = 1.498377 Seconds
Exclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
88.1 1.320 1.320 1 1.3200 1.3200 SDL::SetVideoMode
38.1 0.571 0.774 294 0.0019 0.0026 main::draw_quad_face
16.0 0.240 0.341 8 0.0300 0.0426 SDL::OpenGL::BEGIN
13.0 0.195 0.195 64722 0.0000 0.0000 SDL::OpenGL::Vertex
11.3 0.170 0.170 1 0.1700 0.1700 DynaLoader::dl_load_file
9.34 0.140 0.020 12 0.0116 0.0017 Exporter::export
6.67 0.100 0.100 1001 0.0001 0.0001 SDL::in
4.00 0.060 0.060 1 0.0600 0.0600 SDL::Init
3.34 0.050 0.847 8 0.0062 0.1059 main::BEGIN
2.00 0.030 0.040 5 0.0060 0.0080 SDL::Event::BEGIN
1.80 0.027 0.801 49 0.0005 0.0163 main::draw_cube
1.47 0.022 0.022 2947 0.0000 0.0000 SDL::OpenGL::End
1.33 0.020 0.020 1 0.0200 0.0200 warnings::BEGIN
1.33 0.020 0.020 16 0.0012 0.0012 Exporter::as_heavy
1.33 0.020 0.209 5 0.0040 0.0418 SDL::BEGIN
这个输出有几个问题。数字显然很荒谬(88% 的时间花在 SDL::SetVideoMode 上?),各种 BEGIN 块的统计信息与任务无关且碍事,顶部的错误消息相当令人不安。为了解决这些问题,dprofpp 有 -g 选项,它告诉 dprofpp 只显示特定例程及其后代的统计信息
$ dprofpp -g main::main_loop
Total Elapsed Time = 4.952042 Seconds
User+System Time = 0.812051 Seconds
Exclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
70.3 0.571 0.774 294 0.0019 0.0026 main::draw_quad_face
24.0 0.195 0.195 64722 0.0000 0.0000 SDL::OpenGL::Vertex
3.32 0.027 0.801 49 0.0005 0.0163 main::draw_cube
2.71 0.022 0.022 2947 0.0000 0.0000 SDL::OpenGL::End
1.23 0.010 0.010 49 0.0002 0.0002 SDL::OpenGL::Rotate
1.11 0.009 0.009 7 0.0013 0.0013 main::prep_frame
1.11 0.009 0.009 70 0.0001 0.0001 SDL::OpenGL::Color
0.25 0.002 0.002 2947 0.0000 0.0000 SDL::OpenGL::Begin
0.00 - -0.000 1 - - main::action_quit
0.00 - -0.000 2 - - SDL::EventType
0.00 - -0.000 2 - - SDL::Event::type
0.00 - -0.000 7 - - SDL::GetTicks
0.00 - -0.000 7 - - SDL::OpenGL::Clear
0.00 - -0.000 7 - - SDL::OpenGL::GL_NORMALIZE
0.00 - -0.000 7 - - SDL::OpenGL::GL_SPOT_EXPONENT
您可能已经注意到,我指定了 main::main_loop 而不是仅仅 main_loop。 dprofpp 总是使用完全限定名,如果您使用没有 main:: 包限定符的 main_loop,它将给出空的结果。
在这个排他性时间视图中,第一列的百分比和行顺序仅取决于每个例程的运行时间,而不考虑其子项。仅使用此视图,我可能会尝试以某种方式优化 draw_quad_face,因为它似乎是最昂贵的例程。但这不是最佳方法,因为包容视图(-I)显示
$ dprofpp -I -g main::main_loop
Total Elapsed Time = 4.952042 Seconds
User+System Time = 0.812051 Seconds
Inclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
100. - 0.814 7 - 0.1163 main::do_frame
99.9 - 0.812 1 - 0.8121 main::main_loop
99.7 - 0.810 7 - 0.1158 main::draw_view
99.2 - 0.806 7 - 0.1151 main::draw_frame
98.6 0.027 0.801 49 0.0005 0.0163 main::draw_cube
95.3 0.571 0.774 294 0.0019 0.0026 main::draw_quad_face
24.0 0.195 0.195 64722 0.0000 0.0000 SDL::OpenGL::Vertex
2.71 0.022 0.022 2947 0.0000 0.0000 SDL::OpenGL::End
1.23 0.010 0.010 49 0.0002 0.0002 SDL::OpenGL::Rotate
1.11 0.009 0.009 70 0.0001 0.0001 SDL::OpenGL::Color
1.11 0.009 0.009 7 0.0013 0.0013 main::prep_frame
0.25 0.002 0.002 2947 0.0000 0.0000 SDL::OpenGL::Begin
0.00 - -0.000 1 - - main::action_quit
0.00 - -0.000 2 - - SDL::EventType
0.00 - -0.000 2 - - SDL::Event::type
在这个视图中,draw_quad_face 看起来更糟,因为第一列现在包括其中所有 OpenGL 调用所花费的时间,包括数十万个 glVertex 调用。看起来我应该做些什么来加快它的速度,但到目前为止,如何简化它或减少它执行的 OpenGL 调用数量(除了减少每个面的细分级别,这会降低渲染质量)还不完全清楚。
实际上,有一个更好的选择。真正的问题是 draw_cube 占据了执行时间,而 draw_quad_face 占据了那个。在正常渲染期间完全调用 draw_cube(因此 draw_quad_face)怎么样?告诉 OpenGL 每帧多次告诉 OpenGL 如何渲染一个立方体面似乎非常浪费。如果能够告诉 OpenGL 一次记住立方体定义,然后在引擎需要绘制它时只引用该定义,那会怎么样。
显示列表
我想没有人会对 OpenGL 提供的正是这个功能,即 显示列表 功能感到惊讶。显示列表是一系列 OpenGL 命令,用于执行某个功能。OpenGL 驱动器将其存储(有时以略微优化的格式),而后续代码通过数字引用它。稍后,程序可以请求 OpenGL 运行某些特定列表中的命令,直到所需次数。列表甚至可以调用其他列表;自行车模型可能会调用两次轮子显示列表,而轮子显示列表本身可能会调用数十次辐条显示列表。
我为每个想要建模的形状添加了 init_models 来创建显示列表
sub init_models
{
my $self = shift;
my %models = (
cube => \&draw_cube,
);
my $count = keys %models;
my $base = glGenLists($count);
my %display_lists;
foreach my $model (keys %models) {
glNewList($base, GL_COMPILE);
$models{$model}->();
glEndList;
$display_lists{$model} = $base++;
}
$self->{models}{dls} = \%display_lists;
}
%models 将每个模型与其所需的绘制代码关联起来。因为引擎已经知道如何绘制一个立方体,所以我在这里简单地重用了 draw_cube。接下来的两行开始构建显示列表的工作。代码首先确定需要多少个显示列表,然后调用 glGenLists 来分配它们。OpenGL 按顺序编号分配的列表,并返回序列中的第一个数字(即 列表基)。例如,如果代码请求了四个列表,OpenGL 可能将它们编号为 1051、1052、1053 和 1054,然后返回 1051 作为列表基。
对于每个定义的模型,init_models 调用 glNewList 告诉 OpenGL 它准备在编号为 $base 的位置编译新的显示列表。然后 OpenGL 准备将后续的 OpenGL 调用转换为列表中的条目,而不是立即渲染。如果我用 GL_COMPILE_AND_EXECUTE 代替 GL_COMPILE,OpenGL 将同时执行渲染并保存显示列表中的调用。GL_COMPILE_AND_EXECUTE 在代码需要活动的渲染时非常有用。因为 init_models 只是在预存渲染命令,而在此期间不应该有任何渲染发生,所以 GL_COMPILE 是更好的选择。
然后代码调用绘制例程,该例程方便地提交了为新列表所需的所有 OpenGL 调用。调用 glEndList 然后告诉 OpenGL 停止记录显示列表中的条目并返回正常操作。然后模型循环将当前模型使用的显示列表编号记录在 %display_lists 哈希中,并为下一次迭代增加 $base。在处理完所有模型后,init_models 将 %display_lists 保存到引擎对象中的新结构中。
init 在调用 init_objects 之前调用 init_models。
$self->init_models;
$self->init_objects;
有了这样的初始化,下一步是修改 draw_view 以从模型或绘制例程中绘制。为此,我用以下代码替换了 $o->{draw}->() 调用
if ($o->{model}) {
my $dl = $self->{models}{dls}{$o->{model}};
glCallList($dl);
}
else {
$o->{draw}->();
}
如果对象有相关的模型,draw_view 在 init_models 创建的哈希中查找显示列表,然后使用 glCallList 调用列表。否则,draw_view 回退到像以前一样调用对象的绘制例程。快速运行确认了回退功能正常,添加 init_models 没有破坏任何东西,因此可以安全地将 init_objects 修改为使用模型而不是绘制例程来绘制立方体。这只需要替换三行——我将每个 to 替换为
draw =& \&draw_cube,
到
model =& 'cube',
突然之间,引擎变得 非常 快速和响应。运行 dprofpp 确认了这一点
$ dprofpp -Q -p step068
Done.
$ dprofpp -I -g main::main_loop
Total Elapsed Time = 4.053240 Seconds
User+System Time = 0.973250 Seconds
Inclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
99.9 - 0.973 1 - 0.9733 main::main_loop
86.5 0.024 0.842 413 0.0001 0.0020 main::do_frame
58.1 0.203 0.566 413 0.0005 0.0014 main::draw_view
56.9 0.016 0.554 413 0.0000 0.0013 main::draw_frame
20.1 0.196 0.196 413 0.0005 0.0005 SDL::GLSwapBuffers
19.3 - 0.188 413 - 0.0005 SDL::App::sync
18.4 - 0.180 413 - 0.0004 main::end_frame
16.7 0.163 0.163 2891 0.0001 0.0001 SDL::OpenGL::CallList
9.14 0.028 0.089 413 0.0001 0.0002 main::do_events
8.53 0.035 0.083 413 0.0001 0.0002 main::prep_frame
6.68 0.008 0.065 413 0.0000 0.0002 main::process_events
5.03 0.049 0.049 3304 0.0000 0.0000 SDL::OpenGL::GL_LIGHTING
4.93 0.002 0.048 413 0.0000 0.0001 SDL::Event::pump
4.73 0.046 0.046 413 0.0001 0.0001 SDL::PumpEvents
4.11 0.012 0.040 413 0.0000 0.0001 main::update_time
请注意,在进行分析之前,我必须再次运行 dprofpp -Q -p 并使用新代码,否则 dprofpp 将会重用旧的 tmon.out。
在本报告的第一件事是注意,以前引擎在超时前只能管理七个帧(对 do_frame 的调用),但现在在相同的时间内管理了 413 个!其次,正如预期的那样,main_loop 永远不调用 draw_cube,因为它已经用 glCallList 调用替换了所有这样的调用。因此,不再需要在每一帧中执行成千上万的底层 OpenGL 调用来绘制场景,附带 Perl 和 XS 开销。相反,OpenGL 驱动程序内部处理所有这些调用,开销最小。
这项技术具有额外的优势,现在可以在一台计算机上运行引擎并在另一台计算机上显示窗口,因为显示计算机上的OpenGL驱动程序会保存显示列表。一旦init_models编译了显示列表,它们就会被加载到显示驱动程序中,未来的帧只需要最小的网络流量来处理glCallList。喜欢冒险的用户可以通过在显示计算机上本地登录,使用ssh连接到具有引擎和SDL_perl的计算机,并在那里运行程序来实现这一点。如果你的ssh已经开启了X11转发,你应该会得到一个本地窗口。这确实是件值得高兴的事情。
帧数计数器
dprofpp执行的测量有足够的开销,可以显著降低引擎的显示性能。(即使是旧硬件也能比这个简单场景的80-100 FPS做得更好。)虽然这种开销是进行详细分析所必需的,但当展示性能时,大多数用户都希望有一个显示性能尽可能快的帧率。
制作帧率显示需要能够在场景之前渲染文本的能力。为此所需的组件包括
- 包含要显示字符的符号的字体(至少包括0到9)。
- 一个字体阅读器,用于将字体从文件加载到内存中作为位图。
- 一个将原始位图转换为OpenGL可以轻松显示的格式的转换器。
- 渲染给定字符串的正确位图的方法。
- 计算当前帧率的方法。
数字字体
虽然有很多免费字体,但它们大多数都只以相当复杂的字体格式(如TrueType和Type 1)提供。一些SDL_perl版本支持这些复杂的字体格式,但历史上有许多令人沮丧的错误或不完整。
考虑到相对简单的要求(渲染单个整数),我选择为这篇文章创建一个非常简单的位图字体格式。字体文件位于示例tarball中的numbers-7x11.txt。以下是其开头部分
7x11
30
..000..
.0...0.
.0...0.
0.....0
0.....0
0.....0
0.....0
0.....0
.0...0.
.0...0.
..000..
31
...0...
..00...
00.0...
...0...
...0...
...0...
...0...
...0...
...0...
...0...
0000000
第一行表示字体中每个字符单元的大小;在这种情况下,七列和十一行。剩余的块每个都由字符的十六进制代码点和表示为文本的位图组成——.表示透明像素,0表示渲染像素。空行分隔块。
字体阅读器
为了将符号定义读取到位图中,我首先添加了read_font_file
sub read_font_file
{
my $self = shift;
my $file = shift;
open my $defs, '<', $file
or die "Could not open '$file': $!";
local $/ = '';
my $header = <$defs>;
chomp($header);
my ($w, $h) = split /x/ =& $header;
my %bitmaps;
while (my $def = <$defs>) {
my ($hex, @rows) = grep /\S/ =& split /\n/ =& $def;
@rows = map {tr/.0/01/; pack 'B*' =& $_} @rows;
my $bitmap = join '' =& reverse @rows;
my $codepoint = hex $hex;
$bitmaps{$codepoint} = $bitmap;
}
return (\%bitmaps, $w, $h);
}
read_font_file首先打开字体文件进行读取。然后通过将$/设置为''请求段落吸墨模式。在这种模式下,Perl自动在空行处拆分字体文件,首先是标题,然后是每个完整的符号定义作为一个单独的块。接下来,该程序读取标题,删除尾随空格,并将单元格大小定义拆分为宽度和高度。
完成初步工作后,read_font_file创建一个散列来存储完成的位图,并进入一个while循环,遍历字体文件的剩余块。每个符号定义被拆分为一个十六进制数字和一个位图行数组;使用grep /\S/ =&忽略任何尾随空白行。
下一行将文本行转换为实际的位字符串。首先,每个透明像素(.)变为0,每个渲染像素(0)变为1。将结果二进制文本字符串传递给pack 'B*'将二进制转换为实际的位字符串,位从每个字节的最高位开始打包(如OpenGL所偏好)。结果位字符串存储回@rows。
由于OpenGL偏好从底部开始向上排列位图,代码在join之前反转了@rows以创建完成的位图。hex运算符将十六进制数转换为十进制数,作为新创建的位图在%bitmaps散列中的键。
在解析整个字体文件之后,函数将位图和单元格大小度量返回给调用者。
用OpenGL的语言说话
read_font_file生成的位图只是简单的位串,在这种情况下长度为11字节(每行七像素一个字节)。在使用它们来渲染字符串之前,引擎必须首先将这些位图加载到OpenGL中。这发生在主要的init_fonts例程中。
sub init_fonts
{
my $self = shift;
my %fonts = (
numbers =& 'numbers-7x11.txt',
);
glPixelStore(GL_UNPACK_ALIGNMENT, 1);
foreach my $font (keys %fonts) {
my ($bitmaps, $w, $h) =
$self->read_font_file($fonts{$font});
my @cps = sort {$a <=& $b} keys %$bitmaps;
my $max_cp = $cps[-1];
my $base = glGenLists($max_cp + 1);
foreach my $codepoint (@cps) {
glNewList($base + $codepoint, GL_COMPILE);
glBitmap($w, $h, 0, 0, $w + 2, 0,
$bitmaps->{$codepoint});
glEndList;
}
$self->{fonts}{$font}{base} = $base;
}
}
init_fonts以一个散列开始,将每个已知字体与字体文件关联起来;目前,只定义了numbers字体。实际工作从glPixelStore调用开始,该调用告诉OpenGL所有位图的行都是紧密打包的(沿一个字节边界),而不是填充的,因此每行从偶数的两个、四个或八个字节内存位置开始。
主字体循环首先调用read_font_file将当前字体的位图加载到内存中。下一行将代码点排序到@cps中,下一行通过简单地取@cps中的最后一个找到最大的代码点。
glGenLists调用为代码点0到$max_cp分配显示列表,这些列表将从$base到$base + $max_cp的数字。对于字体定义的每个代码点,内部循环使用glNewList开始编译适当的列表,使用glBitmap将位图加载到OpenGL中,最后使用glEndList完成列表的编译。
glBitmap调用除了位图数据本身($bitmaps->{$codepoint})之外还有六个参数。前两个是位图在像素中的宽度和高度,这是read_font_file方便提供的。接下来两个定义了位图的原点,从左下角开始计算。位图字体使用非零原点用于多个目的,通常在字形超出“正常”左下角时。这可能是因为字形有一个悬垂线(低于一般文本行的字形部分,如小写字母“p”和“y”),或者可能是因为字体向左倾斜。在init_fonts中的简单代码假设没有这些特殊情况适用,并将原点设置为(0,0)。
最后两个参数是X和Y的增量,OpenGL在绘制下一个字符之前应该在X和Y轴上移动的距离。从左到右的语言使用具有正X和零Y增量的字体;从右到左的语言使用负X和零Y。从上到下的语言使用零X和负Y。增量必须包括字符本身的宽度和/或高度以及为提供适当间距所需的任何额外距离。在这种情况下,渲染将是从左到右。我想要两个额外的像素用于间距,所以我将X增量设置为宽度加二,Y增量为零。
外循环的最后一条语句只是简单地保存字体列表基础,以便在渲染期间稍后使用。
init在调用init_time之后像往常一样调用init_fonts
$self->init_fonts;
文本渲染
现在最难的部分已经完成:解析字体文件并将位图加载到OpenGL中。新的draw_fps例程计算并渲染帧率。
sub draw_fps
{
my $self = shift;
my $base = $self->{fonts}{numbers}{base};
my $d_time = $self->{world}{d_time} || 0.001;
my $fps = int(1 / $d_time);
glColor(1, 1, 1);
glRasterPos(10, 10, 0);
glListBase($base);
glCallListsScalar($fps);
}
该例程首先检索numbers字体的列表基,获取当前帧的世界时间差,并计算当前帧速为$d_time秒内的一个帧。需要小心确保$d_time不为零,即使引擎运行得非常快,以至于在一毫秒内渲染一个帧(SDL时间处理的精度);否则,$fps计算会因为除以零错误而失败。
OpenGL部分首先通过调用glColor将当前绘图颜色设置为白色。下一行设置光栅位置,即放置下一个位图的窗口坐标。渲染每个位图后,自动使用位图的X和Y增量更新光栅位置,以防止位图相互重叠。在这种情况下,(10, 10, 0)将光栅位置设置为窗口左下角上方和右侧各十像素,Z=0。
接下来的两行实际上为$fps字符串中的每个字符调用我们位图字体中适当的显示列表。glCallListsScalar将字符串拆分为单个字符,并使用字符的码点数值调用显示列表。例如,对于“5”字符(十进制码点53),glCallListsScalar调用显示列表53。不幸的是,没有保证显示列表53确实会显示“5”,因为字体的列表基可能不是0。例如,如果字体的列表基为1500,则代码需要调用显示列表1500+53=1553来显示“5”。
为了避免每次都手动进行此计算,OpenGL提供了glListBase函数,该函数设置与glCallLists一起使用的列表基。在上面的glListBase调用之后,OpenGL将自动将glCallLists中指定的每个显示列表编号偏移$base。
你可能已经注意到我在代码中使用的是glCallListsScalar,而前面的段落提到的是glCallLists。实际上,glCallListsScalar是SDL_perl扩展(不是核心OpenGL的一部分),它为Perl中的glCallLists提供了不同的调用约定。内部,SDL_perl使用相同的底层OpenGL C函数(glCallLists)实现Perl例程。SDL_perl提供两种不同的调用约定,因为Perl将字符串和数字数组视为两种不同的事物,而C将它们视为本质上相同的事物。
如果你想要渲染一个字符串,并且字符串中的所有字符的码点都小于等于255十进制(单字节字符集,以及大多数变宽字符集的ASCII子集),你可以使用glCallListsScalar,并且它会为你做正确的事。
glCallListsScalar($string);
如果你只想通过单个调用渲染几个显示列表,而且你不想渲染字符串,请使用标准的glCallLists版本。
glCallLists(@lists);
如果你需要渲染一个字符串,但其中包含码点大于255的字符,你必须使用更复杂的解决方案。
glCallLists(map ord($_) =& split // =& $string);
由于FPS计数器仅渲染ASCII数字,第一个选项就足够好了。
draw_frame现在以调用draw_fps结束,如下所示
sub draw_frame
{
my $self = shift;
$self->set_projection_3d;
$self->set_eye_lights;
$self->set_view_3d;
$self->set_world_lights;
$self->draw_view;
$self->draw_fps;
}
目前,我决定通过将init_config中的配置设置更改为0来关闭基准模式。
benchmark =& 0,
在字体处理到位,并且每帧调用draw_fps以在窗口左下角用白色显示帧率的情况下,一切应该都很顺利,如图1所示。
 图1. 绘制帧率
图1. 绘制帧率
哎呀。没有帧率显示。实际上,它在那里,只是非常淡。如果你仔细看(或者将视频卡的伽玛调得非常高),你可以在窗口顶部的大白框上方看到帧率显示。有两个问题——文本太暗,位置也不对。
第一个问题是让人联想到上一篇文章中的黑暗场景,在启用照明但没有灯光的情况下。回想起来,仅仅为了显示统计数据而启用照明并没有太多理由,但最后由draw_view渲染的对象却留下了照明。为了确保照明关闭,我添加了一个set_lighting_2d例程,现在在调用draw_fps之前,draw_frame会调用它。
sub set_lighting_2d
{
glDisable(GL_LIGHTING);
}
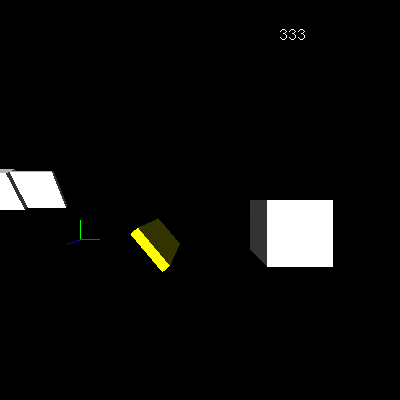 图2. 未开启照明的帧率
图2. 未开启照明的帧率
图2好多了!关闭照明后,帧率现在以预期的明亮白色渲染。下一个问题是位置错误。移动和旋转视点表明,虽然数字始终面向屏幕,但它们的外观位置却在移动(图3)。
 图3. 移动的帧率
图3. 移动的帧率
事实是,当前模型视图和投影矩阵会像glVertex调用的坐标一样变换glRasterPos设置的栅格位置。这意味着OpenGL重用了模型视图和投影矩阵中的任何状态。
为了获得未改变的窗口坐标,我需要使用一个与窗口尺寸匹配的透视投影(没有透视或其它非线性效果)。我还需要设置一个单位模型视图矩阵(这样模型视图矩阵就不会变换坐标)。所有这些都在set_projection_2d中完成,在draw_frame中在调用set_lighting_2d之前调用。
sub set_projection_2d
{
my $self = shift;
my $w = $self->{conf}{width};
my $h = $self->{conf}{height};
glMatrixMode(GL_PROJECTION);
glLoadIdentity;
gluOrtho2D(0, $w, 0, $h);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity;
}
该例程首先从配置哈希中收集窗口宽度和高度。然后切换到投影矩阵(GL_PROJECTION)并在调用gluOrtho2D之前恢复单位状态来创建一个与窗口尺寸匹配的透视投影。最后,切换回模型视图矩阵(GL_MODELVIEW)并恢复其单位状态。现在帧率渲染在预期的左下角位置(图4)。
 图4. 正确的帧率位置
图4. 正确的帧率位置
然而,还有一个更微妙的渲染问题,你可以通过稍微向前移动视点来看到(图5)。
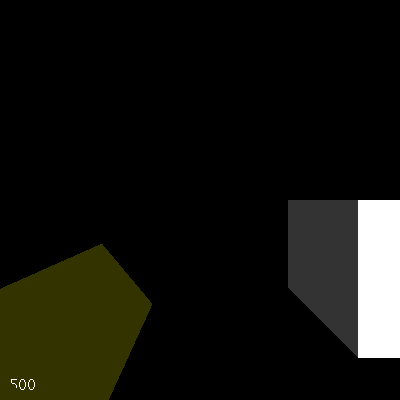 图5. 帧率深度问题
图5. 帧率深度问题
注意“5”部分被切掉了。问题是OpenGL比较了薄黄色框中像素的深度与帧率显示中像素的深度,并发现5中的一些像素比框中的像素更远。实际上,5的一部分绘制在框内。实际上,从这一点稍微向左移动视图会使帧率完全消失,被黄色框的近面隐藏。
这对一个应该看起来悬停在场景前面的统计显示来说并不是很好的行为。解决方案是在set_projection_2d的末尾关闭OpenGL的深度测试。
glDisable(GL_DEPTH_TEST);
有了这个改变,你可以移动视图到任何地方,而不用担心帧率会被切断或完全消失(图6)。
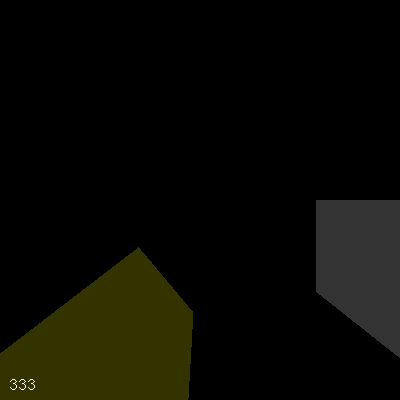 图6. 位置无关的帧率
图6. 位置无关的帧率
太快
还有一个问题;这次需要更改帧率计算。上面截图中的帧率要么是333,要么是500,没有其它值。在这个系统上,帧的渲染时间在两到三毫秒之间,但由于SDL只能提供一毫秒的分辨率,单帧的时间差将显示为正好是0.002秒或0.003秒。1/0.002=500,1/0.003=333,所以显示是一个模糊,在两个可能的值之间闪烁。
为了得到一个更具代表性(并且更易读)的值,代码必须对多个帧的平均帧率进行平均。这样做将使得总测量时间足够长,以至于可以消除SDL时钟的分辨率不足。
我需要的第一件事是初始化帧率数据的例程,以便跨多个帧传递。
sub init_fps
{
my $self = shift;
$self->{stats}{fps}{cur_fps} = 0;
$self->{stats}{fps}{last_frame} = 0;
$self->{stats}{fps}{last_time} = $self->{world}{time};
}
引擎对象中的新stats结构将保存引擎收集的任何关于自身的统计信息。为了计算FPS,引擎需要记住它上次获取时间戳的帧,以及该帧的时间戳。因为引擎只在每隔几个帧计算一次帧率,所以它还会保存上次计算出的FPS值,以便在需要时渲染它。和往常一样,init_fps调用在init的末尾进行。
$self->init_fps;
新的update_fps例程现在计算帧率。
sub update_fps
{
my $self = shift;
my $frame = $self->{state}{frame};
my $time = $self->{world}{time};
my $d_frames = $frame - $self->{stats}{fps}{last_frame};
my $d_time = $time - $self->{stats}{fps}{last_time};
$d_time ||= 0.001;
if ($d_time >= .2) {
$self->{stats}{fps}{last_frame} = $frame;
$self->{stats}{fps}{last_time} = $time;
$self->{stats}{fps}{cur_fps} = int($d_frames / $d_time);
}
}
update_fps首先收集当前帧号和时间戳,并计算从保存的值中得出的增量。同样,$d_time必须默认为0.001秒,以避免稍后可能出现的除以零错误。
if语句检查是否已经过去足够的时间,以便得到一个合理准确的帧率计算。如果是这样,它将最后帧号和时间戳设置为当前值,并将当前帧率设置为$d_frames / $d_time。
update_fps调用必须在main_loop的早期进行,但必须在引擎确定新的帧号和时间戳之后。现在main_loop看起来像这样:
sub main_loop
{
my $self = shift;
while (not $self->{state}{done}) {
$self->{state}{frame}++;
$self->update_time;
$self->update_fps;
$self->do_events;
$self->update_view;
$self->do_frame;
}
}
为了启用新的更精确的显示,需要进行的最后更改是在draw_fps中;$d_time查找被移除,而$fps计算变成了从stats结构中简单检索当前值。
my $fps = $self->{stats}{fps}{cur_fps};
更精确的计算现在可以轻松地看出简单视图(图7)和更复杂视图(图8)之间的帧率差异。
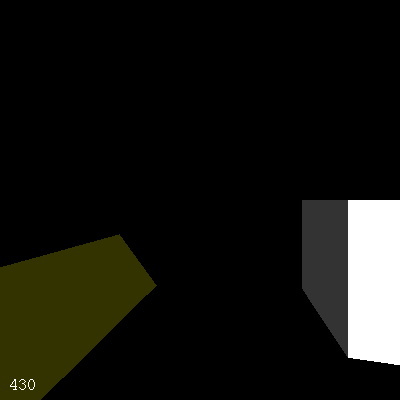 图7. 简单视图的帧率
图7. 简单视图的帧率
以及更复杂视图的帧率(图8)。
 图8. 复杂视图的帧率
图8. 复杂视图的帧率
新的显示是否是瓶颈?
最后一件事是检查这个闪亮的新帧率显示本身是否是主要瓶颈。最容易做到这一点的方法是在init_conf中重新开启基准模式。
benchmark =& 1,
这样做之后,我再次在dprofpp下运行引擎,然后像之前一样分析结果。
$ dprofpp -Q -p step075
Done.
$ dprofpp -I -g main::main_loop
Total Elapsed Time = 3.943764 Seconds
User+System Time = 1.063773 Seconds
Inclusive Times
%Time ExclSec CumulS #Calls sec/call Csec/c Name
100. - 1.064 1 - 1.0638 main::main_loop
94.6 0.006 1.007 384 0.0000 0.0026 main::do_frame
85.2 0.019 0.907 384 0.0000 0.0024 main::draw_frame
50.7 0.205 0.540 384 0.0005 0.0014 main::draw_view
16.8 0.073 0.179 384 0.0002 0.0005 main::draw_fps
15.4 0.095 0.164 384 0.0002 0.0004 main::set_projection_2d
11.6 0.045 0.124 384 0.0001 0.0003 main::draw_axes
10.9 0.116 0.116 2688 0.0000 0.0000 SDL::OpenGL::CallList
8.74 0.013 0.093 384 0.0000 0.0002 main::end_frame
7.52 0.003 0.080 384 0.0000 0.0002 SDL::App::sync
7.24 0.077 0.077 384 0.0002 0.0002 SDL::GLSwapBuffers
4.89 0.052 0.052 3072 0.0000 0.0000 SDL::OpenGL::PopMatrix
4.70 0.023 0.050 384 0.0001 0.0001 main::update_view
3.67 0.039 0.039 3456 0.0000 0.0000 SDL::OpenGL::GL_LIGHTING
3.48 0.037 0.037 384 0.0001 0.0001 SDL::OpenGL::Begin
目前,draw_view占main_loop运行时间的一半,而set_projection_2d和draw_fps的组合占main_loop时间的约三分之一。这是好消息还是坏消息?
由于我刚刚对其进行了优化,所以draw_view现在运行得如此之快。现在它运行得如此快,我可以承担添加更多功能或创建一个更复杂的场景,这将使draw_view再次占据更多的时间。此外,由于任何在窗口中的统计信息、调试或HUD(抬头显示器)都需要set_projection_2d,所以花在这里的时间不会浪费。
这留下了draw_fps,占main_loop运行时间的六分之一。这可能比我想的要大一点,但还不足以证明需要额外努力。我将把我的精力留给下一组功能。
结论
在这篇文章中,我涵盖了与引擎性能相关的几个概念:添加基准模式;使用dprofpp进行剖析;使用显示列表优化缓慢且重复的渲染任务;以及使用显示列表、位图字体和平均来产生平滑的帧率显示。我还为触发事件子系统添加了一个存根,我将在未来的文章中回到这个话题。
随着这些性能提升,引擎已经准备好迎接下一个新特性——纹理表面,这将是下篇文章的主要内容。
在此之前,祝您玩得愉快,享受破解的乐趣!
标签
反馈
这篇文章有什么问题吗?请在GitHub上打开一个问题或拉取请求来帮助我们。
